Cluster · embedding AI
Embedding AI: cosa sono spiegati semplice
Cosa sono gli embedding AI, spiegati semplice: la rappresentazione numerica del significato, come funzionano, esempi reali e a cosa servono in azienda.
Tempo di lettura: 10 min
Guida operativa · Fondamenta AI
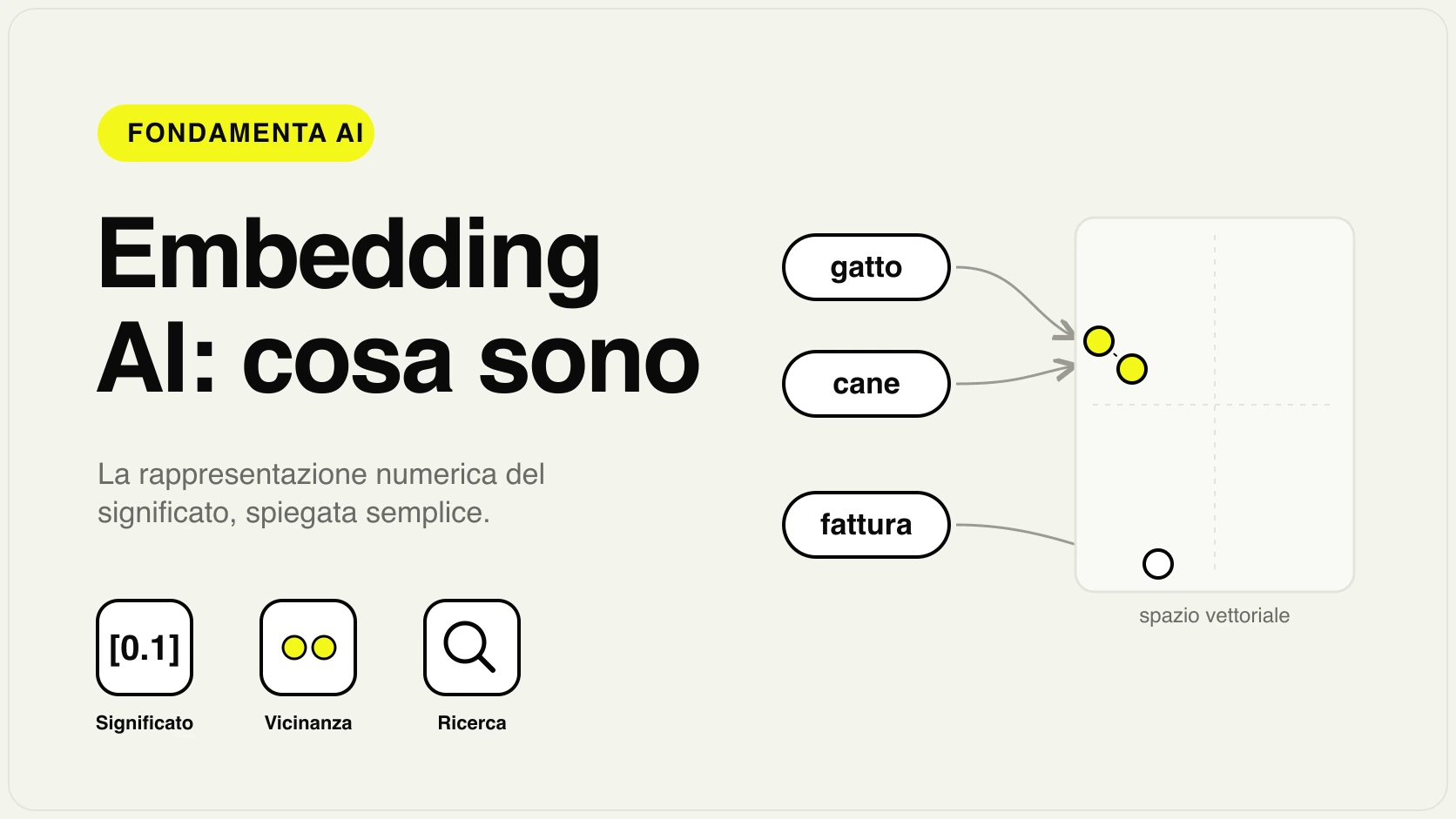
Gli embedding AI sono la rappresentazione numerica del significato di un contenuto: una parola, una frase, un documento o anche un'immagine vengono trasformati in una lista di numeri — un vettore — costruita in modo che contenuti con significato simile abbiano numeri vicini tra loro. In pratica è il modo in cui un'AI smette di vedere "parole" e inizia a vedere "posizioni su una mappa del significato".
L'idea da fissare subito è questa: se due testi parlano della stessa cosa, i loro embedding sono vicini; se parlano di cose diverse, sono lontani. Per questo il software può capire che "rimborso spese" e "nota spese da liquidare" sono affini, anche se non condividono nessuna parola. Gli embedding sono il mattone che rende possibili la ricerca per significato, i sistemi che rispondono sui tuoi documenti e molti suggerimenti automatici.
In questa guida vediamo cosa sono davvero gli embedding, come funziona la "mappa del significato", a cosa servono in azienda e come si collegano a vector database e sistemi RAG in una catena logica precisa.
In sintesi
- Un embedding è la rappresentazione numerica (un vettore) del significato di un testo, un'immagine o un altro contenuto.
- Il principio chiave è la vicinanza semantica: contenuti con significato simile finiscono vicini su una "mappa" fatta di numeri.
- Grazie agli embedding l'AI può cercare per significato, non per parola esatta: trova il documento giusto anche con sinonimi o frasi diverse.
- Gli embedding sono il dato; il vector database è il magazzino che li conserva e cerca, e il RAG è il flusso che li usa per far rispondere un'AI sui tuoi documenti.
- Non "capiscono" come una persona: catturano regolarità statistiche e vanno verificati su gergo di settore, termini ambigui e lingue poco rappresentate.
Cosa sono gli embedding, con un'analogia
Immagina una grande mappa. Su questa mappa non ci sono città, ma significati. Ogni parola, frase o documento occupa un punto preciso. Le cose che vogliono dire qualcosa di simile stanno vicine; quelle scollegate stanno lontane.
In questa mappa "cane", "gatto" e "criceto" sarebbero raggruppati in una zona (animali domestici), mentre "fattura", "preventivo" e "bilancio" starebbero in un quartiere completamente diverso (documenti contabili). Un embedding è semplicemente l'indirizzo di un contenuto su questa mappa, espresso in coordinate.
La differenza con una mappa geografica è che qui le coordinate non sono due (latitudine e longitudine), ma centinaia o migliaia. Ogni numero del vettore descrive una sfumatura di significato. Non ha senso chiedersi "cosa significa il numero 47 del vettore": preso da solo non vuol dire niente. È l'insieme dei numeri, e soprattutto la distanza tra un vettore e l'altro, a portare l'informazione.
Questo è il salto concettuale: l'AI non confronta le parole lettera per lettera, confronta posizioni nello spazio del significato. Ecco perché può collegare "spedizione in ritardo" e "il pacco non è ancora arrivato" pur senza parole in comune.
Come funziona un embedding, passo per passo
Gli embedding non sono scritti a mano: vengono prodotti da un modello addestrato su enormi quantità di testo. Il principio di fondo è lo stesso del machine learning in generale — imparare schemi dai dati invece di programmare regole. Ecco il flusso.
- Input. Dai al modello un contenuto: una parola, una frase, un paragrafo, una scheda prodotto, a volte un'immagine.
- Elaborazione. Il modello, addestrato a riconoscere come i contenuti compaiono insieme nei dati, analizza l'input e ne misura il significato lungo molte dimensioni.
- Vettore. Il risultato è una lista di numeri (per esempio 384, 768 o 1536 valori). Quella lista è l'embedding: l'indirizzo del contenuto sulla mappa del significato.
- Confronto. Per capire se due contenuti sono affini, si misura la distanza tra i loro vettori. Vicini = simili; lontani = diversi.
- Uso. Quella distanza alimenta la funzione che ti serve: ricerca, raggruppamento, raccomandazione, recupero di documenti per un'AI.
Perché conta la "vicinanza" e non l'uguaglianza
Il software tradizionale cerca corrispondenze esatte: se cerchi "fattura" trova solo i testi che contengono la parola "fattura". Se il documento dice "documento fiscale di vendita", non lo trova. È la classica ricerca per parole chiave, fragile davanti ai sinonimi.
Con gli embedding cambi metro: non cerchi la parola, cerchi il significato più vicino. Il sistema trasforma la tua domanda in un vettore e restituisce i contenuti i cui vettori sono più vicini. È quella che si chiama ricerca semantica, ed è il motivo per cui un assistente AI sui documenti aziendali trova la risposta anche quando l'utente la chiede "a parole sue".
Quanto sono grandi questi vettori
La "dimensione" di un embedding è quanti numeri contiene. Più dimensioni permettono di catturare più sfumature, ma occupano più spazio e costano di più da confrontare. Per la maggior parte degli usi aziendali si lavora con vettori da poche centinaia a un paio di migliaia di valori, e la scelta del modello la fa lo strumento o il consulente, non l'utente finale.
A cosa servono gli embedding in azienda
Qui il discorso diventa concreto. Gli embedding non sono un fine, sono l'ingranaggio che fa funzionare alcune cose molto utili. I casi più solidi per una PMI sono pochi e ricorrenti.
- Ricerca interna intelligente: trovare il documento, la procedura o la mail giusta cercando per significato, non per parola esatta.
- Risposte sui documenti aziendali: alimentare un sistema RAG che recupera i passaggi pertinenti e fa rispondere un'AI sui tuoi contenuti, riducendo le invenzioni.
- Raggruppamento automatico: clusterizzare ticket di assistenza, recensioni o richieste simili per capire i temi ricorrenti senza leggerli uno a uno.
- Suggerimenti e correlazioni: prodotti simili in un e-commerce, articoli correlati, "clienti come questo" basati sulla vicinanza dei vettori.
- Deduplica e match: riconoscere che due anagrafiche, due fornitori o due richieste sono in realtà la stessa cosa scritta in modo diverso.
Il filo comune è sempre lo stesso: gli embedding traducono "significato" in "distanza", e sulla distanza puoi costruire ricerca, ordine e suggerimenti. Se vuoi una panoramica più ampia su dove conviene partire, la guida AI per aziende mette in fila processi, costi e priorità.
La catena logica: embedding → vector database → RAG
Questo è il punto che mette ordine in tutto. Gli embedding non lavorano da soli: fanno parte di una catena con due compagni precisi.
| Pezzo | Cos'è | Ruolo nella catena |
|---|---|---|
| Embedding | La rappresentazione numerica del significato di un contenuto | Traduce testi e documenti in vettori confrontabili |
| Vector database | Un archivio specializzato per conservare e cercare vettori | Trova in millisecondi i vettori più vicini a una domanda, anche tra milioni |
| RAG | Il flusso che recupera i contenuti pertinenti e li dà a un modello | Usa i risultati per far rispondere un LLM sui tuoi dati reali |
Letta come sequenza: prendi i tuoi documenti e li trasformi in embedding; li conservi in un vector database; quando arriva una domanda, la trasformi in embedding, il database ti restituisce i passaggi più vicini, e un sistema RAG li passa al modello che scrive la risposta basandosi su di essi. Gli embedding sono il primo anello: senza di loro, gli altri due non hanno niente da cercare.
Esempio della catena con numeri finti
Hai 5.000 pagine di manuali e procedure. Le spezzi in 30.000 paragrafi e generi un embedding per ognuno: ora hai 30.000 vettori. Li carichi nel vector database. Un dipendente chiede "come gestisco un reso oltre i 14 giorni?". La domanda diventa un vettore, il database restituisce i 5 paragrafi più vicini, il sistema RAG li passa al modello che compone la risposta citando le procedure giuste. Tempo totale: una frazione di secondo.
Esempi pratici
Tre scenari realistici di PMI e professionisti italiani, per rendere tangibile l'idea.
1. Studio professionale — ricerca nelle circolari. Uno studio accumula anni di circolari, pareri e note interne. Con la ricerca per parole chiave, trovare il parere giusto dipende dal ricordare le parole esatte usate allora. Generando gli embedding di ogni documento e mettendoli in un vector database, un collaboratore può chiedere "trattamento fiscale degli omaggi ai clienti" e ottenere i documenti pertinenti anche se quelli usavano "spese di rappresentanza in natura". La ricerca segue il significato, non la formula.
2. E-commerce — prodotti correlati che hanno senso. Un negozio con 1.200 articoli vuole suggerire prodotti affini. Invece di regole scritte a mano categoria per categoria, calcola gli embedding delle schede prodotto: gli articoli con descrizioni semanticamente vicine risultano vicini anche come vettori. Risultato: suggerimenti coerenti ("scarpe da trail" vicino a "calze tecniche") senza mantenere a mano migliaia di associazioni.
3. Assistenza clienti — capire i temi dei ticket. Un team riceve centinaia di richieste al mese e vuole sapere di cosa si lamentano davvero i clienti. Trasformando i ticket in embedding e raggruppando i vettori vicini, emergono i temi ricorrenti (ritardi di spedizione, problemi di taglia, dubbi sui resi) senza che qualcuno legga e classifichi a mano ogni messaggio. La squadra interviene sulle cause più frequenti.
In tutti e tre i casi gli embedding non "decidono": preparano il terreno (cercano, raggruppano, collegano) e la persona usa il risultato per agire meglio.
Quando gli embedding aiutano e quando no
Quando convengono
- Hai molti documenti e la ricerca per parole chiave non basta più.
- Gli utenti cercano "a parole loro", con sinonimi e frasi diverse.
- Vuoi raggruppare o collegare contenuti simili in automatico.
- Stai costruendo un assistente che deve rispondere sui tuoi documenti (RAG).
Quando sono eccessivi
- I documenti sono pochi e una ricerca per parole chiave basta e avanza.
- Ti serve una corrispondenza esatta (codice prodotto, partita IVA, numero ordine).
- Il contenuto è molto tecnico e ambiguo e non hai modo di verificare i risultati.
- Stai aggiungendo complessità senza un problema misurabile da risolvere.
Regola pratica: gli embedding brillano sul significato approssimativo ("trovami qualcosa di simile a questo"), non sulle corrispondenze esatte ("trovami esattamente questo codice"). Per i secondi, un database tradizionale resta più adatto. Spesso la soluzione migliore è combinare i due.
Errori da evitare
- Confondere embedding e database. L'embedding è il numero; il vector database è il magazzino che lo cerca. Sono due cose diverse della stessa catena: chiamarli allo stesso modo porta a scelte tecniche sbagliate.
- Mischiare modelli diversi. I vettori prodotti da modelli diversi non sono confrontabili. Se generi metà dei documenti con un modello e metà con un altro, le distanze diventano insensate. Un solo modello per tutto l'archivio.
- Spezzare male i documenti. Se trasformi in embedding pezzi troppo lunghi o tagliati a metà frase, recuperi contenuti confusi. La qualità del chunking (come dividi i testi) pesa quanto il modello.
- Fidarsi al 100% della vicinanza. "Vicino" non vuol dire "corretto". Su termini ambigui o gergo di settore il vettore più vicino può non essere la risposta giusta: serve verifica, soprattutto in un flusso RAG.
- Mettere dati sensibili senza criterio. Generare embedding di documenti con dati personali tramite servizi esterni può avere implicazioni GDPR. Vanno definite regole su cosa si può inviare e dove vengono conservati i vettori.
Come applicarlo in azienda
Introdurre gli embedding in modo sensato è un percorso a tappe, non un grande progetto tecnico.
- Parti dal problema, non dalla tecnologia. "La ricerca interna non trova niente" o "perdiamo tempo a cercare nei documenti" è un buon punto di partenza. "Vogliamo gli embedding" non lo è.
- Raccogli e prepara i contenuti. Documenti, schede, ticket: vanno raccolti e spezzati in pezzi sensati prima di trasformarli in vettori.
- Scegli modello e magazzino. Un modello di embedding e un vector database adatti al volume. Spesso bastano servizi gestiti, non infrastruttura su misura.
- Collega il tutto a un flusso utile. Ricerca interna, raggruppamento o un assistente RAG. L'embedding da solo non si vede: si vede il risultato che abilita.
- Misura e correggi. I risultati sono pertinenti? Gli utenti trovano quello che cercano? Si aggiusta il chunking, il modello o le istruzioni e si itera.
Questo tipo di lavoro — capire dove la ricerca semantica conviene davvero e costruire la catena embedding → database → RAG senza sprechi — è esattamente il terreno di una buona consulenza AI e di progetti di automazione dei processi aziendali. Per applicazioni più strutturate, gli stessi mattoni alimentano agenti AI che cercano, recuperano e agiscono sui dati interni.
Conclusione
Gli embedding AI sono la traduzione del significato in numeri: una mappa dove i contenuti affini stanno vicini e quelli scollegati stanno lontani. È un'idea semplice con conseguenze potenti, perché trasforma la domanda "questi due testi parlano della stessa cosa?" in una semplice misura di distanza. Da soli non fanno nulla: diventano utili quando entrano nella catena con il vector database, che li conserva e li cerca, e con il RAG, che li usa per far rispondere un modello sui tuoi documenti reali. Per una PMI il valore non sta nella matematica dei vettori, ma nello scegliere il caso d'uso — ricerca interna, raggruppamento, assistente sui documenti — e misurarne il risultato.
Vuoi capire quali processi della tua azienda possono essere automatizzati con l'AI? Giallo Studio può aiutarti a trasformare il problema in un workflow reale — oppure dai un'occhiata agli esperimenti del The Lab.
Risorse correlate

FAQ
Cosa sono gli embedding AI in parole semplici?
Gli embedding sono la rappresentazione numerica del significato di un testo, di un'immagine o di un altro contenuto. L'AI trasforma una parola o una frase in una lista di numeri (un vettore) costruita in modo che contenuti con significato simile abbiano numeri vicini. È così che il software può capire che 'fattura' e 'documento contabile' parlano della stessa cosa pur essendo parole diverse.
A cosa servono gli embedding in azienda?
Servono soprattutto a cercare per significato e non per parola esatta. Con gli embedding puoi costruire una ricerca interna che trova il documento giusto anche se l'utente usa sinonimi, raggruppare automaticamente ticket o recensioni simili, suggerire prodotti correlati e alimentare un sistema RAG che fa rispondere un'AI sui tuoi documenti aziendali.
Qual è la differenza tra embedding e vector database?
L'embedding è il numero (il vettore) che rappresenta il significato di un contenuto. Il vector database è il magazzino specializzato che conserva milioni di questi vettori e trova in pochi millisecondi quelli più vicini a una domanda. Gli embedding sono il dato; il vector database è il motore che li cerca.
Gli embedding capiscono davvero il significato?
Non nel senso umano. Gli embedding catturano regolarità statistiche di come le parole compaiono insieme nei dati di addestramento, e questo riproduce molto bene la vicinanza di significato per la maggior parte dei casi pratici. Ma possono sbagliare su termini ambigui, gergo specifico del tuo settore o lingue poco rappresentate.
Servono competenze tecniche per usare gli embedding?
Per usarli a fondo serve un minimo di lavoro tecnico, ma quasi mai bisogna costruirli da zero. La maggior parte delle PMI li usa tramite strumenti già pronti o servizi che li generano via API, collegandoli a documenti, CRM o e-commerce esistenti. Il valore sta nello scegliere il caso d'uso giusto, non nella matematica dei vettori.
Gli embedding sono la stessa cosa dei token?
No, anche se sono collegati. I token sono i pezzi in cui un modello spezza il testo per elaborarlo; gli embedding sono i numeri che rappresentano il significato di quei pezzi (o di interi testi). Detto in breve: il token è l'unità, l'embedding è il significato di quell'unità tradotto in coordinate.