Cluster · RAG
RAG: cos'è e perché migliora le risposte AI
Cos'è il RAG (retrieval augmented generation) e perché rende le risposte AI più precise: come funziona, esempi reali e come usarlo in azienda.
Tempo di lettura: 10 min
Guida operativa · Fondamenta AI
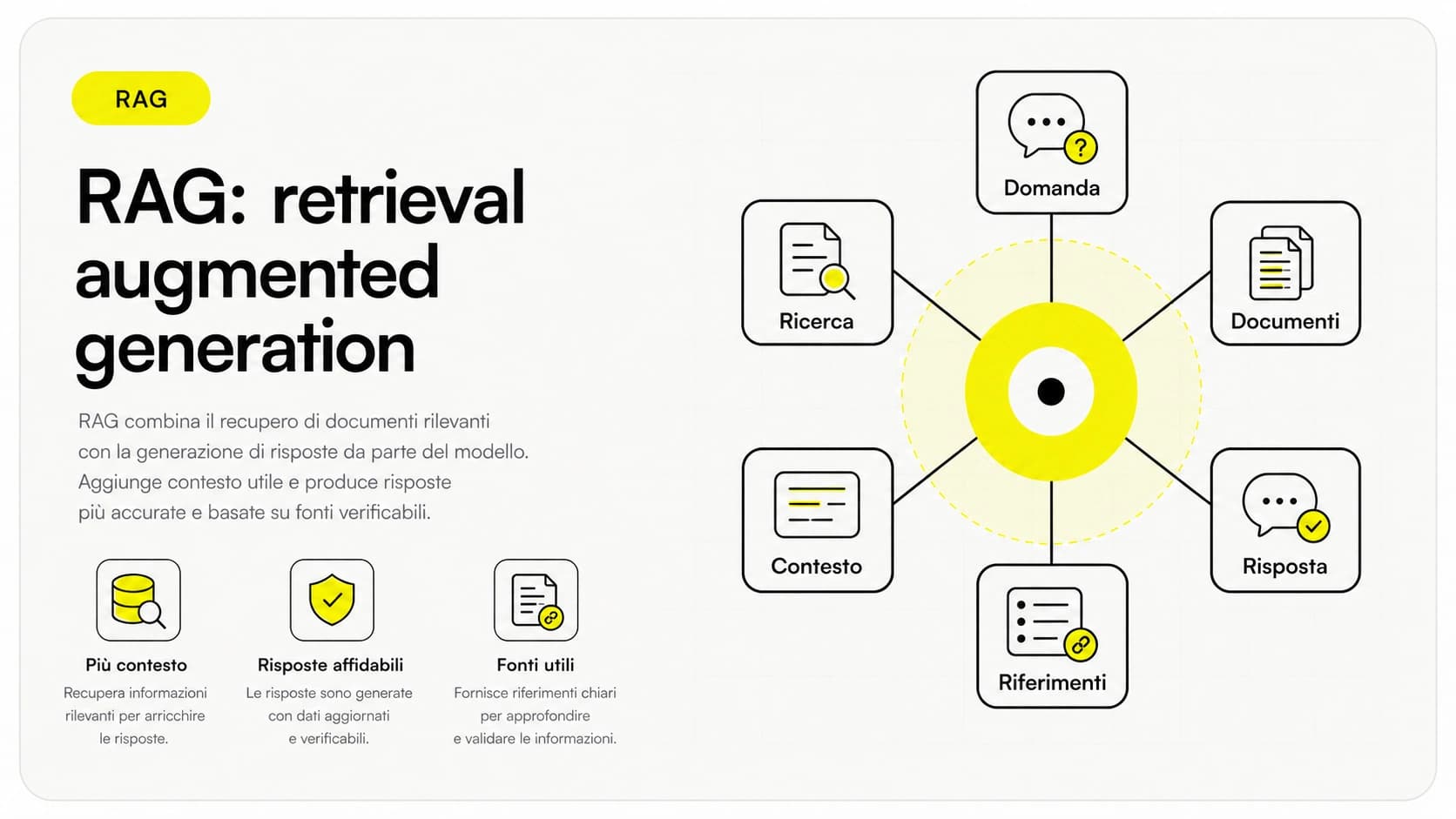
Il RAG (sigla di retrieval augmented generation, in italiano "generazione aumentata dal recupero") è una tecnica che collega un modello AI ai tuoi documenti: prima cerca i passaggi rilevanti nella tua base di conoscenza, poi li passa al modello perché costruisca la risposta basandosi su quelli. In pratica l'AI smette di rispondere "a memoria" e risponde leggendo i tuoi dati reali, citando da dove arriva l'informazione.
Perché conta? Un modello linguistico come ChatGPT o Claude conosce solo ciò che ha visto durante l'addestramento: non sa nulla del tuo listino, dei tuoi contratti o delle tue procedure interne. Se glielo chiedi senza dargli il contesto, inventa una risposta plausibile invece di ammettere che non sa. Il RAG risolve esattamente questo: fornisce al modello i documenti giusti al momento giusto, così le risposte diventano specifiche, aggiornate e verificabili.
In questa guida vediamo cos'è davvero il RAG, come funziona passo per passo (documenti → embedding → vector database → recupero → generazione con citazioni), quando conviene rispetto ad altre strade e come una PMI può usarlo su una propria knowledge base.
In sintesi
- Il RAG collega un modello AI ai tuoi documenti: recupera i passaggi rilevanti e li usa per generare la risposta, invece di rispondere solo "a memoria".
- Serve a far rispondere l'AI su contenuti che il modello non ha mai visto: manuali, procedure, contratti, knowledge base aziendale.
- Il flusso è: documenti → embedding → vector database → recupero dei passaggi più simili → generazione con citazioni.
- Riduce molto le allucinazioni e permette di citare la fonte, ma non le azzera: serve sempre controllo umano sui casi critici.
- Rispetto al fine-tuning è più semplice ed economico quando i dati cambiano spesso: aggiorni i documenti, non riaddestri il modello.
Cosa significa RAG (retrieval augmented generation)
La sigla RAG mette insieme tre parole che descrivono esattamente cosa succede: retrieval (recupero), augmented (aumentata), generation (generazione). Tradotto: la generazione della risposta da parte del modello viene aumentata dal recupero di informazioni pertinenti da una fonte esterna.
Per capire perché serve, parti da un limite preciso dei modelli linguistici. Un LLM è addestrato su un'enorme quantità di testo fino a una certa data, poi "congelato". Da quel momento:
- non conosce i tuoi dati privati (il tuo CRM, i tuoi manuali, i tuoi prezzi);
- non sa nulla di ciò che è successo dopo l'addestramento;
- quando non sa, tende a inventare una risposta che suona corretta.
Il RAG non cambia il modello: gli mette accanto un "motore di ricerca" sui tuoi contenuti. Prima di rispondere, il sistema cerca nei tuoi documenti i pezzi più attinenti alla domanda e li incolla nel contesto del modello, insieme alla domanda stessa. Il modello legge quei pezzi e risponde su quelli. È come passare da uno studente che risponde a memoria a uno studente con il libro aperto alla pagina giusta.
Come funziona il RAG, passo per passo
Il RAG si divide in due momenti: una fase di preparazione (una tantum, quando carichi i documenti) e una fase di risposta (ogni volta che qualcuno fa una domanda). Vediamole come un unico flusso operativo.
- Documenti. Si parte dalla tua knowledge base: manuali, FAQ, procedure, contratti, schede prodotto. I file vengono divisi in pezzi più piccoli e coerenti (i cosiddetti chunk), perché un intero PDF è troppo grande da gestire in un colpo solo.
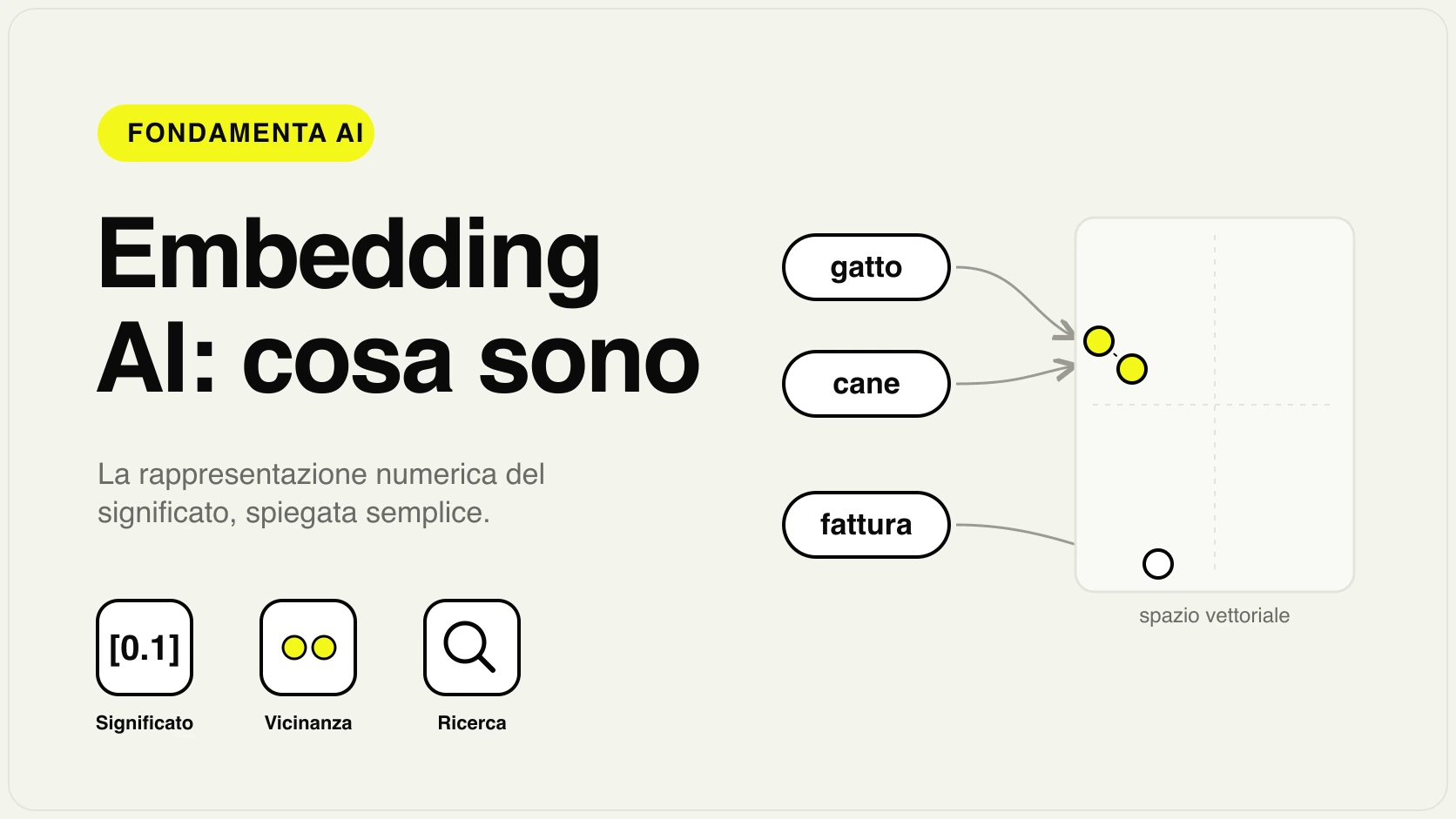
- Embedding. Ogni pezzo di testo viene trasformato in un vettore di numeri che ne rappresenta il significato. Testi che parlano della stessa cosa producono vettori vicini tra loro. Questo è il cuore tecnico: gli embedding trasformano le parole in coordinate confrontabili.
- Vector database. Tutti questi vettori vengono salvati in un vector database, un archivio pensato per trovare in millisecondi i vettori più simili a uno dato. È l'indice della tua biblioteca.
- Recupero (retrieval). Quando arriva una domanda, anche la domanda viene trasformata in embedding. Il vector database restituisce i pezzi di documento il cui significato è più vicino a quello della domanda — di solito i 3-8 più rilevanti.
- Generazione con citazioni. Quei passaggi vengono passati al modello insieme alla domanda. Il modello scrive la risposta basandosi sui testi recuperati e indica da quale documento arriva l'informazione, così la fonte è verificabile.
Perché gli embedding e il vector database sono il motore
La parte che fa la differenza è il recupero per significato, non per parole esatte. Una ricerca tradizionale trova solo i documenti che contengono le stesse parole della domanda. Il RAG, grazie agli embedding, trova i documenti che parlano della stessa cosa anche con parole diverse: se l'utente chiede "posso restituire un articolo difettoso?" il sistema recupera la sezione del manuale intitolata "politica di reso e garanzia", anche se non contiene la parola "restituire".
Il vector database è ciò che rende questa ricerca veloce su migliaia o milioni di pezzi: senza di lui, confrontare la domanda con ogni documento sarebbe troppo lento per un assistente che deve rispondere in tempo reale.
Cosa cambia rispetto a un LLM "nudo"
LLM da solo
- Risponde solo con ciò che ha imparato in addestramento.
- Non conosce i tuoi documenti né i dati recenti.
- Quando non sa, tende a inventare.
- Non può citare una fonte verificabile.
LLM con RAG
- Risponde leggendo i tuoi documenti reali.
- Si aggiorna quando aggiorni la knowledge base.
- Quando il contesto manca, può dire "non lo so".
- Mostra da quale documento arriva la risposta.
RAG o fine-tuning: quale serve davvero
Sono spesso messi in alternativa, ma rispondono a esigenze diverse. Il fine-tuning riaddestra il modello su nuovi esempi per cambiarne lo stile o il comportamento; il RAG non tocca il modello e gli fornisce la conoscenza al momento della domanda.
| Criterio | RAG | Fine-tuning |
|---|---|---|
| A cosa serve | Dare al modello accesso a dati e documenti specifici | Cambiare stile, tono o formato delle risposte |
| Dati che cambiano spesso | Ideale: aggiorni i documenti, non il modello | Scomodo: ogni cambiamento richiede un nuovo addestramento |
| Costo iniziale | Più basso, parte da strumenti pronti | Più alto, richiede dati di addestramento e calcolo |
| Citare le fonti | Sì, può indicare il documento | No, la conoscenza è "fusa" nel modello |
| Rischio di inventare | Ridotto (risponde sui testi recuperati) | Resta, se la domanda esce dagli esempi visti |
| Quando preferirlo | Knowledge base aziendale, FAQ, supporto, ricerca interna | Stile molto specifico, formati rigidi, gergo tecnico costante |
Nella maggior parte dei casi aziendali — "voglio che l'AI risponda sui miei documenti" — la risposta giusta è il RAG. Il fine-tuning entra in gioco quando il problema non è cosa sa il modello, ma come risponde. Approfondisci la differenza nella guida sul fine-tuning AI e quando serve.
Esempi pratici
Tre scenari realistici di PMI e professionisti italiani, per rendere concreto il RAG.
1. Studio commercialista — assistente sulla normativa interna. Lo studio ha centinaia di circolari, prassi e procedure interne. Un assistente RAG indicizza tutti questi documenti: quando un collaboratore chiede "come gestiamo il regime forfettario per un nuovo cliente?", il sistema recupera la procedura aggiornata dello studio e risponde citandola, invece di dare una risposta generica presa dal web. Le fonti citate permettono di verificare al volo. È lo stesso tipo di lavoro descritto nella pagina dedicata all'AI per i commercialisti.
2. E-commerce — supporto clienti sui propri contenuti. Un negozio online collega un assistente alle proprie pagine di spedizioni, resi, garanzia e schede prodotto. Il cliente chiede "quanto ci mette ad arrivare in Sicilia?" e l'assistente risponde con i tempi reali presi dalla pagina spedizioni, non con una stima inventata. Quando l'azienda cambia il corriere, basta aggiornare il documento: la risposta cambia subito, senza toccare il modello.
3. Azienda manifatturiera — manuali tecnici. Centinaia di pagine di manuali di macchinari. Un tecnico in officina chiede dal telefono "qual è la procedura di reset dell'errore E-204 sulla linea 3?" e l'assistente recupera il passaggio esatto del manuale corretto e lo cita. Il tempo per trovare l'informazione passa da minuti di ricerca tra i PDF a pochi secondi.
In tutti e tre i casi il valore non è "l'AI sa tutto", ma "l'AI risponde sui documenti giusti e ti dice da dove ha preso la risposta".
Quando il RAG conviene e quando no
Quando usare il RAG
- Hai una base di documenti specifica su cui far rispondere l'AI.
- I contenuti cambiano nel tempo e vanno tenuti aggiornati.
- Ti serve poter citare la fonte per fidarti della risposta.
- Vuoi ridurre le invenzioni del modello su argomenti tuoi.
Quando non serve (o non basta)
- La domanda è generica e il modello base risponde già bene.
- I documenti sono pochi e stabili: a volte basta incollarli nel prompt.
- Il problema è lo stile della risposta: lì serve il fine-tuning.
- I documenti sono disordinati o errati: vanno prima sistemati.
Errori da evitare
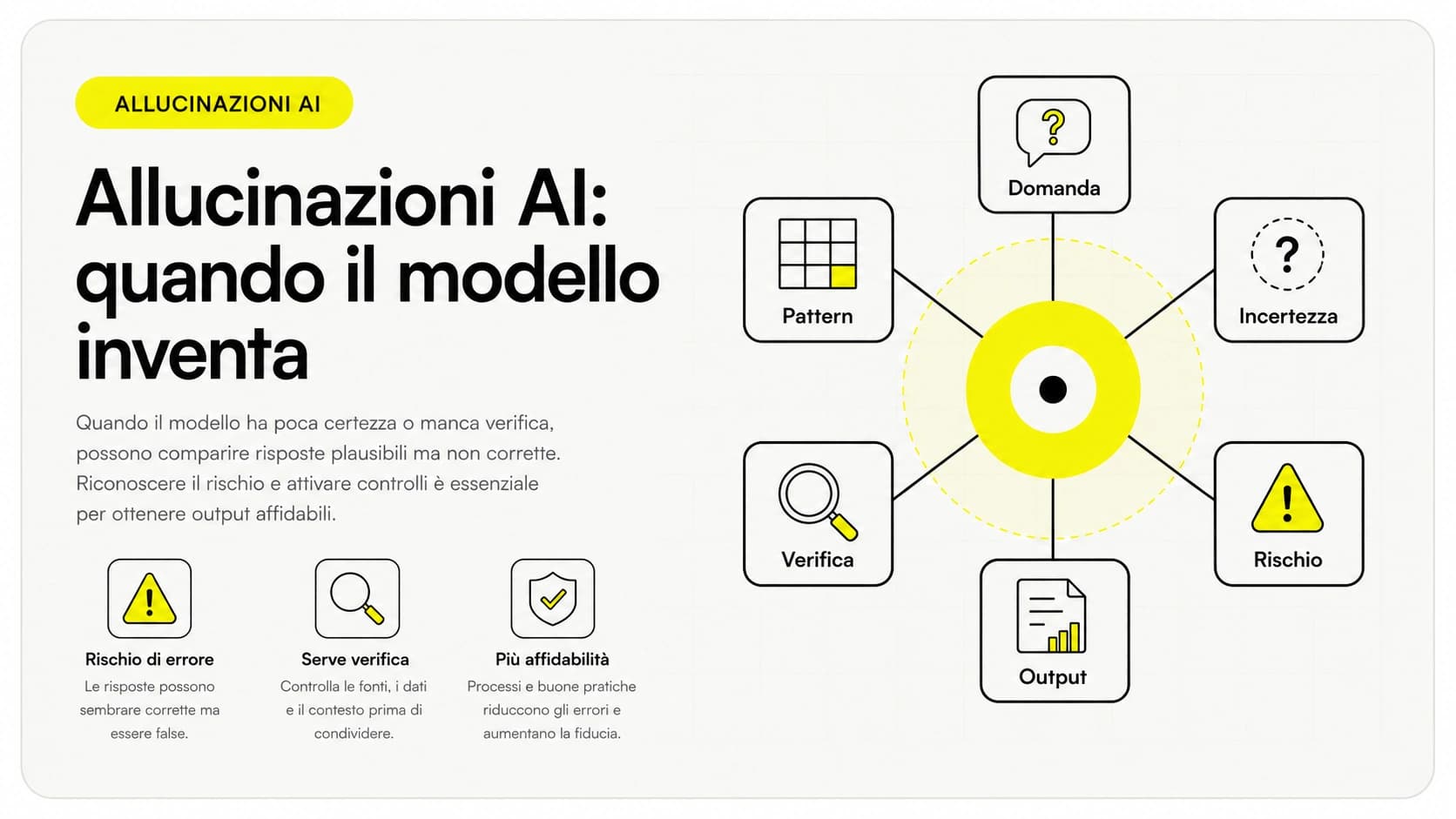
- Pensare che il RAG azzeri le allucinazioni. Le riduce, non le elimina. Se il recupero porta passaggi sbagliati, il modello può comunque generare una risposta imprecisa. Tieni sempre visibili le fonti e prevedi una revisione umana sui casi critici. Approfondisci nella guida sulle allucinazioni AI.
- Caricare documenti disordinati. PDF scansionati male, versioni doppie, contenuti contraddittori: il sistema recupererà confusione. La preparazione dei documenti è la parte che decide il risultato, non un dettaglio.
- Dividere male i documenti in chunk. Pezzi troppo grandi diluiscono il significato; troppo piccoli perdono il contesto. Una buona suddivisione è ciò che fa trovare il passaggio giusto.
- Non aggiornare la knowledge base. Il vantaggio del RAG è restare attuale, ma solo se qualcuno aggiorna davvero i documenti. Una base ferma a due anni fa dà risposte vecchie con sicurezza.
- Esporre dati sensibili senza controllo. Indicizzare contratti o dati di clienti in strumenti pubblici può violare il GDPR. Servono regole chiare su cosa entra nella knowledge base e chi può interrogarla.
Come applicarlo in azienda
Costruire un sistema RAG utile è un percorso ordinato, non un salto tecnologico. Ecco i passaggi che funzionano per una PMI.
- Scegli una base documentale circoscritta e ad alto valore (es. le FAQ del supporto o un manuale), non "tutti i file aziendali" insieme.
- Pulisci e aggiorna quei documenti: elimina versioni doppie, correggi gli errori, dai una struttura coerente.
- Decidi chi potrà fare domande e su cosa, definendo i confini di accesso ai dati sensibili.
- Parti da strumenti già pronti: spesso non serve costruire tutto da zero per un primo sistema.
- Mostra sempre le fonti citate e misura quante risposte sono corrette prima di estendere ad altre aree.
Il RAG è uno dei mattoni più richiesti quando un'azienda vuole un assistente che risponda sui propri contenuti. Spesso diventa la base di un agente AI che non solo trova l'informazione, ma compie azioni — aggiornare un ticket, preparare una bozza, smistare una richiesta. Per inquadrare priorità, costi e processi della tua azienda, la guida AI per aziende raccoglie il percorso completo per partire.
Tradurre tutto questo in un sistema che funziona sui tuoi documenti è esattamente il lavoro di una consulenza AI: capire quale knowledge base ha senso indicizzare, preparare i dati e collegare l'assistente ai tuoi strumenti. Se vuoi vedere prototipi e sperimentazioni concrete, dai un'occhiata al The Lab.
Conclusione
Il RAG è la tecnica che fa passare l'AI dal "rispondere a memoria" al "rispondere leggendo i tuoi documenti". Il flusso è semplice da ricordare — documenti, embedding, vector database, recupero dei passaggi rilevanti, generazione con citazioni — ma cambia la qualità delle risposte: più specifiche, più aggiornate e soprattutto verificabili. Per una PMI è spesso la strada più rapida ed economica per avere un assistente che conosce davvero la propria azienda, a patto di partire da documenti puliti e di tenere la persona nel controllo sui casi critici.
Se vuoi passare dai test con ChatGPT a un sistema AI integrato nei processi aziendali, Giallo Studio progetta agenti e automazioni su misura — incluso un sistema RAG sui tuoi documenti reali.
Risorse correlate

FAQ
Cos'è il RAG in parole semplici?
RAG (retrieval augmented generation) è una tecnica che collega un modello AI ai tuoi documenti: prima cerca i passaggi rilevanti nella tua knowledge base, poi li passa al modello perché generi la risposta basandosi su quelli. In pratica il modello smette di rispondere 'a memoria' e risponde leggendo i tuoi dati reali.
A cosa serve il RAG?
Serve a far rispondere un assistente AI sui contenuti specifici della tua azienda — manuali, procedure, contratti, documentazione — che il modello non ha mai visto in addestramento. Riduce le invenzioni, permette di citare la fonte e mantiene le risposte aggiornate quando aggiorni i documenti, senza riaddestrare nulla.
Qual è la differenza tra RAG e fine-tuning?
Il fine-tuning modifica il modello riaddestrandolo su nuovi esempi, è costoso e va rifatto quando i dati cambiano. Il RAG lascia il modello invariato e gli fornisce i documenti giusti al momento della domanda. Per far rispondere l'AI su una knowledge base che cambia spesso, il RAG è quasi sempre la scelta più semplice ed economica.
Il RAG elimina del tutto le allucinazioni?
No, le riduce ma non le azzera. Se il recupero porta passaggi sbagliati o incompleti, il modello può comunque generare una risposta imprecisa. Per questo un buon sistema RAG mostra le fonti citate, così la persona può verificare, e prevede una revisione umana sui casi critici.
Serve un vector database per fare RAG?
Nella maggior parte dei casi sì: il vector database conserva gli embedding dei tuoi documenti e trova in millisecondi i passaggi più simili alla domanda. Su pochi documenti si può partire anche con soluzioni più semplici, ma quando la knowledge base cresce un database vettoriale rende la ricerca veloce e affidabile.
Quanto serve per mettere il RAG in un'azienda?
Per un primo sistema su una base documentale circoscritta (es. le FAQ o un manuale) bastano poche settimane, usando strumenti già pronti. Il lavoro vero non è tecnico ma di preparazione: documenti puliti, aggiornati e ben organizzati. La qualità delle risposte dipende più dalla qualità dei dati che dal modello scelto.