Cluster · machine learning
Machine learning: cos'è e come funziona
Cos'è il machine learning e come funziona, spiegato semplice: tipi di apprendimento, esempi reali in azienda, differenza con l'AI, limiti e usi pratici.
Tempo di lettura: 11 min
Guida operativa · Fondamenta AI
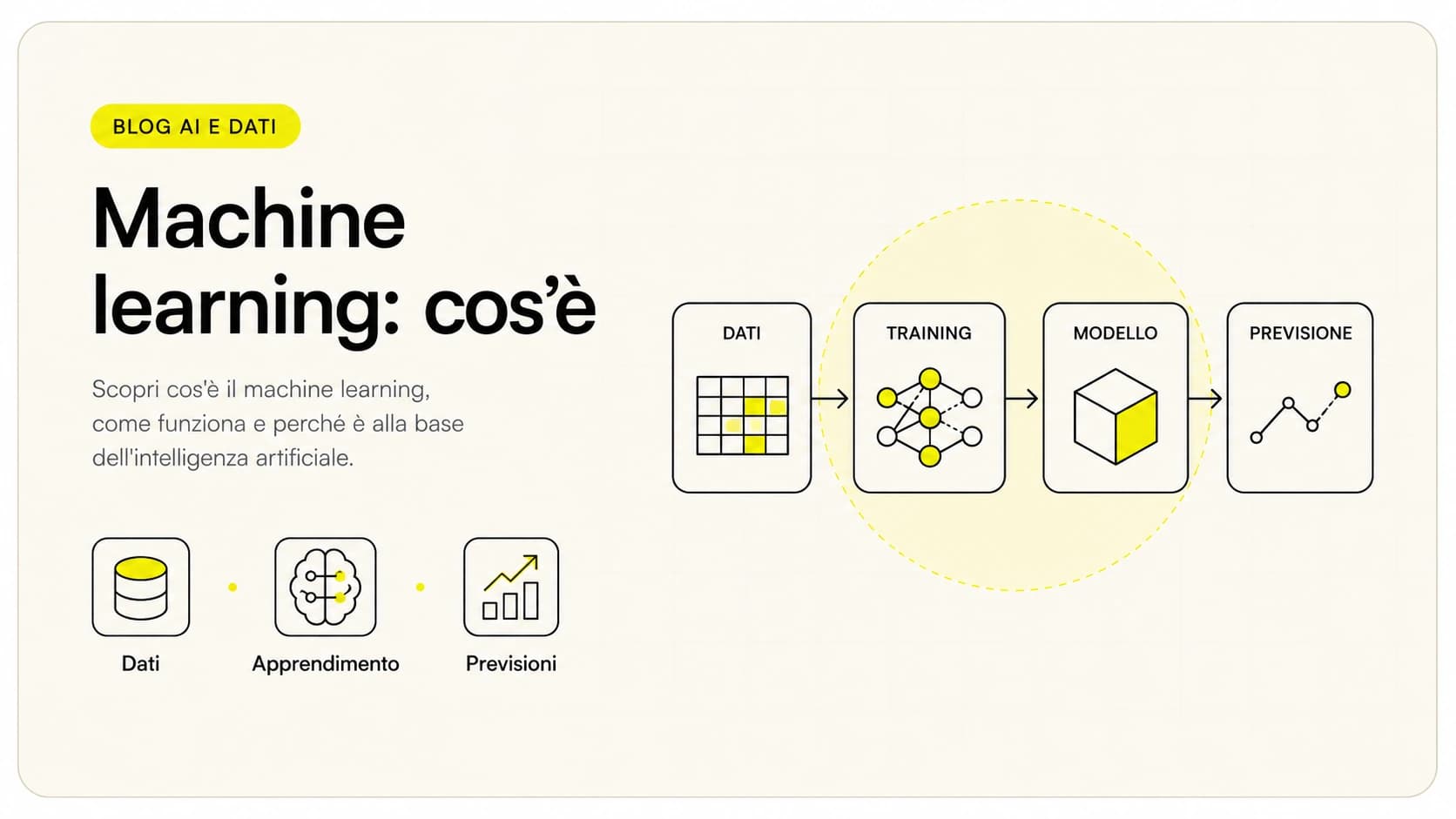
Il machine learning (in italiano apprendimento automatico) è il metodo con cui un software impara a svolgere un compito a partire dagli esempi, invece di seguire regole scritte a mano da un programmatore. Gli si mostrano migliaia di casi già risolti — email già marcate come spam, transazioni già classificate come fraudolente, vendite già registrate — e il sistema ricava da solo gli schemi che gli servono per gestire casi nuovi.
È la tecnologia che sta sotto a quasi tutta l'intelligenza artificiale che usiamo oggi: i filtri antispam, i suggerimenti di prodotti, la previsione delle vendite, il riconoscimento vocale e perfino i modelli che generano testo. La differenza con il software tradizionale è netta: invece di dire alla macchina come fare una cosa, le mostri molti esempi di cosa vuoi ottenere e la lasci imparare la regola.
In questa guida vediamo cos'è davvero il machine learning, come funziona passo per passo, quali tipi esistono, dove ha senso usarlo in una PMI e quali sono i suoi limiti concreti.
In sintesi
- Il machine learning fa imparare un software dagli esempi: non scrivi le regole, le ricava lui dai dati.
- È un sottoinsieme dell'intelligenza artificiale: l'AI è l'obiettivo, il machine learning è il metodo più usato per raggiungerlo.
- I tre tipi principali sono supervisionato (esempi etichettati), non supervisionato (schemi senza etichette) e per rinforzo (tentativi ed errori con premi).
- Il deep learning è una sua versione basata su reti neurali profonde, più potente ma più esigente in dati e calcolo.
- La qualità del risultato dipende dalla qualità dei dati: dati sporchi o non rappresentativi producono modelli inaffidabili.
- Per una PMI il valore non sta nell'algoritmo, ma nello scegliere un problema con dati e un risultato misurabile.
Cosa significa "machine learning"
Il termine machine learning indica la branca dell'informatica che studia come far migliorare un programma nello svolgere un compito man mano che viene esposto a più dati. La definizione classica, di Tom Mitchell, dice che un programma impara se le sue prestazioni su un compito migliorano con l'esperienza. In pratica: più esempi vede, meglio lavora.
La differenza rispetto alla programmazione tradizionale è il cuore di tutto. Nel software classico un umano scrive ogni regola, una per una. Nel machine learning si mostra al sistema l'input e l'output desiderato, e il sistema ricava da solo la regola che li collega. Questo lo rende molto più adatto ai problemi pieni di sfumature, dove scrivere tutte le regole a mano sarebbe impossibile.
Per capire dove si colloca, conviene avere chiare le scatole una dentro l'altra: l'intelligenza artificiale è la più grande (il campo che vuole far fare a una macchina compiti intelligenti); il machine learning è dentro l'AI (il metodo per imparare dai dati); il deep learning è dentro il machine learning (i modelli basati su reti neurali profonde). Se vuoi il quadro generale che le contiene tutte, parti dalla guida su cos'è l'intelligenza artificiale.
Come funziona il machine learning, passo per passo
Quasi tutti i progetti di machine learning seguono lo stesso flusso: si parte dai dati, si addestra un modello, lo si valuta e lo si usa per fare previsioni su dati nuovi. Vediamolo come sequenza operativa.
- Raccolta dei dati. Si mettono insieme gli esempi: storico vendite, email già smistate, transazioni, schede prodotto. Senza dati rappresentativi non c'è apprendimento possibile.
- Preparazione e pulizia. I dati grezzi vanno ripuliti: campi mancanti, duplicati, formati incoerenti. Questa fase, spesso noiosa, pesa più di metà del lavoro reale.
- Addestramento. Un algoritmo analizza gli esempi e regola i parametri interni del modello finché impara a collegare gli input agli output corretti.
- Validazione. Si testa il modello su dati che non ha mai visto, per misurare quanto è accurato davvero e non solo "a memoria" sui dati di addestramento.
- Messa in produzione (inferenza). Il modello riceve dati nuovi reali e produce le previsioni che servono al processo aziendale.
- Monitoraggio. Le prestazioni vanno tenute d'occhio nel tempo: se il mondo cambia, il modello si "deteriora" e va riaddestrato con dati freschi.
Cosa significa "addestrare un modello"
Addestrare un modello vuol dire trovare i parametri che fanno collegare al meglio gli input agli output. Immagina di voler prevedere il prezzo di un appartamento dai metri quadri: il modello cerca la relazione (più metri, più prezzo) che meglio si adatta agli esempi reali. Con problemi semplici i parametri sono pochi; con il deep learning diventano milioni o miliardi.
Un concetto chiave è il generalizzare: un buon modello non deve solo "azzeccare" gli esempi di addestramento, ma funzionare bene su casi nuovi. Quando impara a memoria i dati di partenza e fallisce sui nuovi, si parla di overfitting — uno degli errori più comuni e insidiosi.
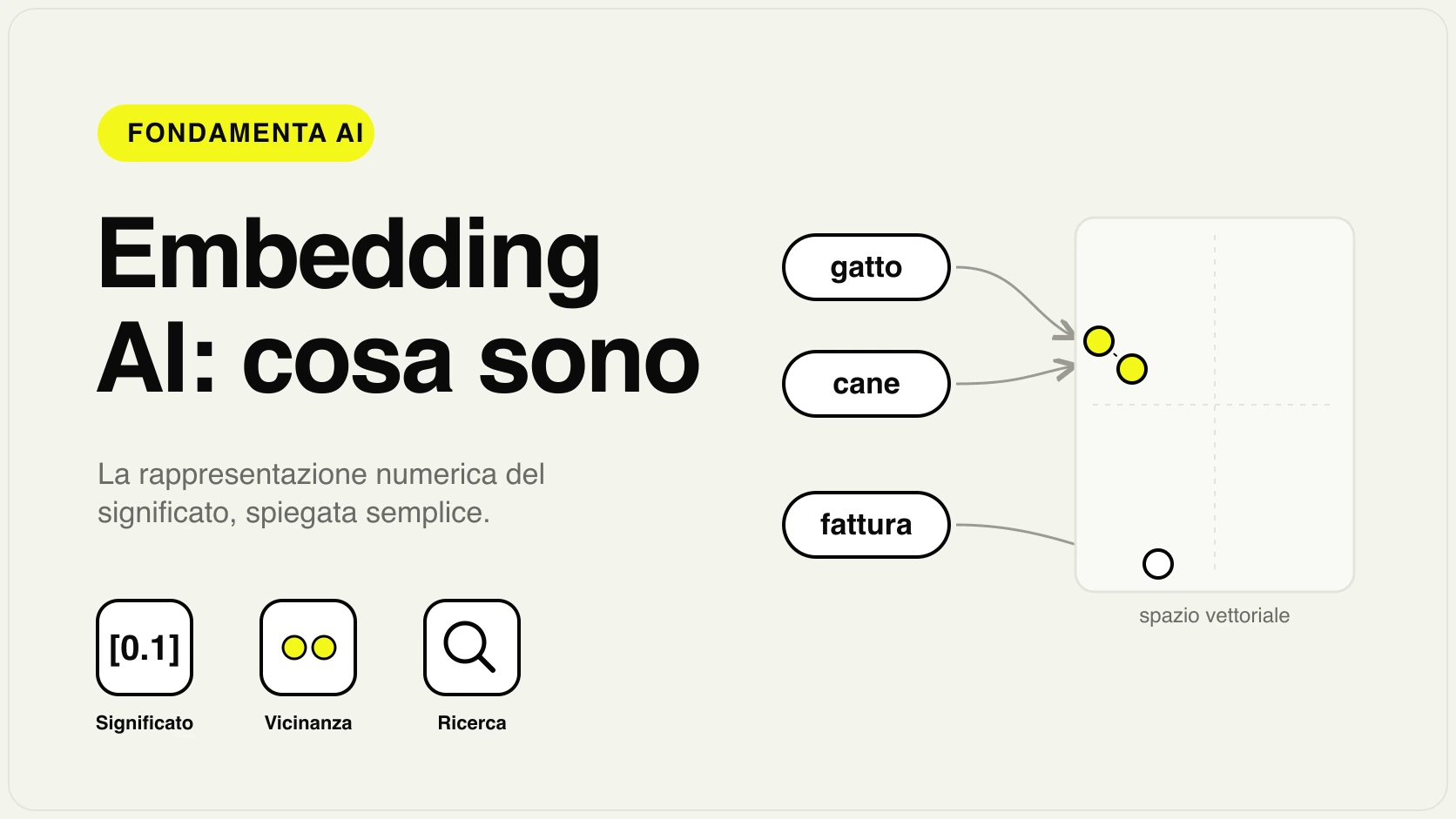
Come la macchina "rappresenta" i dati
Gli algoritmi non lavorano su parole o immagini, ma su numeri. Un testo, un cliente o un prodotto vengono trasformati in liste di numeri che ne catturano le caratteristiche. Nei sistemi moderni questa rappresentazione numerica si chiama embedding: è ciò che permette al modello di capire, per esempio, che "rimborso" e "reso" sono concetti vicini. Capire questo passaggio aiuta a vedere perché la qualità e la pulizia dei dati contano così tanto.
Quali tipi di machine learning esistono
Non tutto il machine learning funziona allo stesso modo. Le famiglie principali si distinguono per come il sistema impara: con esempi etichettati, senza etichette, o per tentativi. Ecco le tre più importanti, con cosa fanno e un esempio aziendale.
| Tipo di machine learning | Come impara | Esempio concreto in azienda |
|---|---|---|
| Supervisionato | Da esempi già "etichettati" con la risposta corretta | Classificare email in spam/non spam; prevedere se un cliente abbandonerà |
| Non supervisionato | Trova gruppi e schemi senza risposte fornite | Segmentare i clienti per comportamento d'acquisto; trovare anomalie nei dati |
| Per rinforzo | Per tentativi ed errori, con premi e penalità | Ottimizzare prezzi dinamici; gestione di magazzino o logistica |
| Semi-supervisionato | Pochi esempi etichettati + molti non etichettati | Classificare documenti quando etichettarli tutti a mano costa troppo |
Nella pratica aziendale il caso più frequente è di gran lunga il supervisionato: hai uno storico di casi già risolti e vuoi prevedere il prossimo. La maggior parte dei progetti utili — previsioni, classificazioni, rilevamento frodi — rientra qui.
Supervisionato vs non supervisionato: come scelgo?
Usa l'apprendimento supervisionato quando hai uno storico con la "risposta giusta" già nota: vendite passate, ticket già categorizzati, clienti che hanno o non hanno disdetto. L'obiettivo è prevedere quella risposta su casi nuovi.
Usa l'apprendimento non supervisionato quando non hai etichette e vuoi scoprire struttura nei dati: raggruppare clienti simili, individuare transazioni anomale, capire quali prodotti vengono comprati insieme. Non prevede una risposta nota: ti mostra schemi che non avevi visto.
A cosa serve il machine learning in azienda
Il punto pratico è questo: il machine learning serve a fare previsioni e classificazioni su grandi volumi, lì dove un umano sarebbe troppo lento o incoerente. Non sostituisce il giudizio: prepara il terreno perché la persona decida meglio e più in fretta. I casi più solidi per una PMI sono pochi e ricorrenti.
- Previsione: stimare vendite, domanda, scorte di magazzino o flussi di cassa dai dati storici.
- Classificazione: smistare automaticamente email, ticket e documenti nelle categorie giuste.
- Rilevamento anomalie: individuare frodi, errori contabili o comportamenti fuori norma.
- Segmentazione: raggruppare clienti per comportamento per personalizzare offerte e comunicazioni.
- Raccomandazione: suggerire il prodotto o la prossima azione più rilevante in un e-commerce o in un CRM.
Il filo comune è che il machine learning lavora sui dati strutturati che la tua azienda già produce ogni giorno e che spesso restano inutilizzati. La differenza con l'AI generativa — quella di ChatGPT e simili — è che la generativa crea contenuti nuovi, mentre il machine learning "classico" prevede e classifica. Le due cose oggi si combinano spesso nello stesso flusso.
Esempi pratici
Tre scenari realistici di PMI italiane, per rendere concreto il discorso.
1. E-commerce — previsione della domanda. Un negozio online con 1.200 referenze vuole evitare sia il sovra-stock sia le rotture di stock. Un modello supervisionato impara dallo storico di vendite, stagionalità e promozioni, e stima quanti pezzi serviranno nelle prossime settimane per ogni prodotto. Il responsabile acquisti rivede le stime e ordina con più margine. Risultato tipico: meno capitale immobilizzato in magazzino e meno mancate vendite.
2. Studio commercialista — classificazione documenti. Ogni giorno arrivano centinaia di documenti diversi (fatture, F24, contratti, estratti conto). Un modello di classificazione, addestrato su migliaia di documenti già archiviati, riconosce di che tipo si tratta e propone la cartella corretta. L'operatore conferma o corregge i casi dubbi, e quelle correzioni migliorano il modello nel tempo. È il mattone su cui si costruisce poi l'automazione del processo.
3. Azienda di servizi — previsione abbandono clienti. Un fornitore di servizi in abbonamento vuole capire quali clienti rischiano di disdire. Un modello impara dallo storico (frequenza d'uso, ticket aperti, ritardi nei pagamenti) e assegna a ogni cliente un punteggio di rischio. Il team commerciale contatta in via prioritaria quelli ad alto rischio, prima che se ne vadano. La previsione non è una certezza, ma sposta l'attenzione dove conta.
In tutti e tre i casi il machine learning non "decide": fornisce una stima ben informata, e la persona agisce di conseguenza. È il modello che funziona.
Quando ha senso usare il machine learning e quando no
Quando conviene
- Hai uno storico di dati sufficiente e abbastanza pulito.
- Il compito è ripetitivo e ad alto volume, difficile da gestire con regole fisse.
- Esistono schemi reali nei dati (il passato dice qualcosa sul futuro).
- Un margine di errore è tollerabile, o c'è una revisione umana sui casi critici.
Quando evitarlo (per ora)
- Hai pochi dati, sporchi o non rappresentativi del problema.
- Bastano poche regole chiare e stabili: un sistema a regole è più semplice e trasparente.
- Ogni errore ha conseguenze gravi e non c'è controllo umano.
- Il fenomeno cambia in continuazione e il passato non aiuta a prevedere il futuro.
Regola pratica: senza dati buoni non c'è machine learning utile. Se i dati sono pochi o disordinati, il primo investimento non è l'algoritmo ma la raccolta e la pulizia. Un modello addestrato su dati scadenti produce previsioni scadenti, presentate però con la stessa sicurezza di quelle buone — ed è proprio questo a renderlo pericoloso.
Errori da evitare
- Puntare al modello prima dei dati. Si parte sempre dai dati disponibili e dalla loro qualità, non dall'algoritmo "di moda". Senza dati rappresentativi, nessun modello salva il progetto.
- Confondere accuratezza alta con modello buono. Un modello che "azzecca" tutti gli esempi di addestramento ma fallisce sui casi nuovi soffre di overfitting: ha imparato a memoria, non ha generalizzato. Si valuta sempre su dati mai visti.
- Ignorare i bias nei dati. Il modello eredita i pregiudizi presenti nei dati storici: se in passato le decisioni erano distorte, le riprodurrà. Su clienti, candidati e credito è un rischio concreto, anche legale.
- Dimenticare che i modelli "invecchiano". Un modello addestrato l'anno scorso può non valere più: mercato, clienti e prezzi cambiano. Senza monitoraggio e riaddestramento, le previsioni peggiorano in silenzio.
- Trattare la previsione come certezza. Il machine learning dà probabilità, non verità. Su decisioni importanti serve sempre un controllo umano e una stima dell'incertezza.
Come applicarlo in azienda
Introdurre il machine learning in modo sensato è un percorso a tappe, non un grande progetto da reparto IT. Vale anche per una PMI senza data scientist interni.
- Parti da una domanda di business, non dalla tecnologia. "Quali clienti rischiano di andarsene?", "Quanti pezzi ordino il mese prossimo?". Una domanda chiara guida tutto il resto.
- Verifica se hai i dati. Esiste uno storico utilizzabile? È abbastanza pulito e accessibile? Se no, il primo passo è organizzarlo, non addestrare nulla.
- Definisci come misurerai il successo. Accuratezza minima accettabile, errore tollerabile, valore atteso (ore o costi risparmiati). Senza un metro non saprai se funziona.
- Parti dal modello più semplice che basta. Spesso un approccio classico è più trasparente, più rapido e più che sufficiente. La complessità si aggiunge solo se serve davvero.
- Tieni l'umano nel controllo e misura di nuovo. Il modello propone, la persona decide e corregge. Quelle correzioni alimentano il miglioramento successivo.
Questo è esattamente il tipo di lavoro che una consulenza AI può accompagnare: capire se il problema è adatto al machine learning, valutare i dati e collegare il modello ai processi reali. Spesso il modello è solo un pezzo, e il valore arriva quando entra in un'automazione dei processi o dentro un agente AI che agisce in autonomia sui casi semplici.
Conclusione
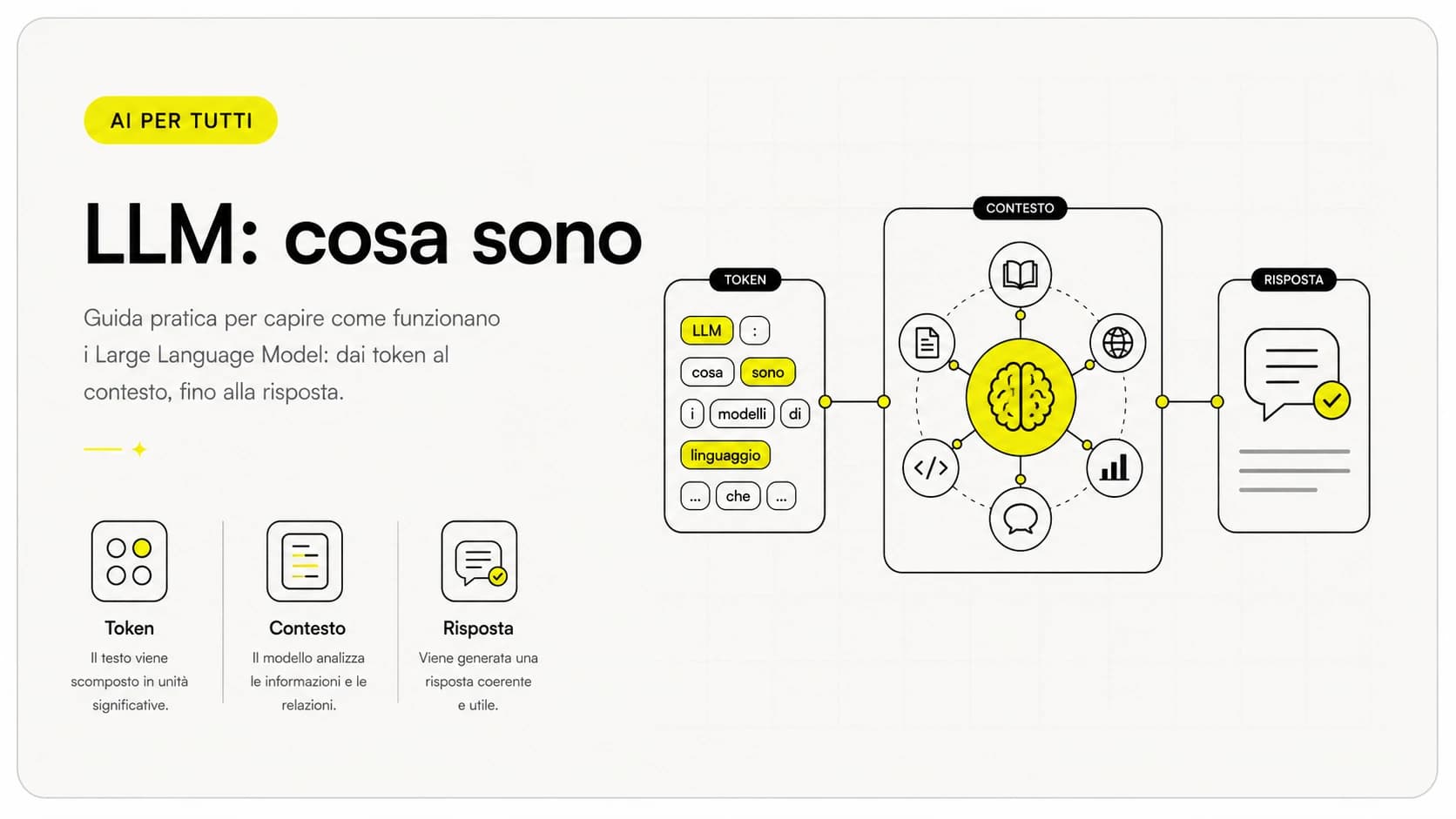
Il machine learning è il motore di quasi tutta l'AI pratica di oggi: un software che impara dagli esempi a fare previsioni e classificazioni, invece di seguire regole scritte a mano. La sua forza sta nel gestire volumi e sfumature che nessuna regola fissa potrebbe coprire; il suo limite sta nel dipendere interamente dalla qualità dei dati e nel fornire probabilità, non certezze. Per una PMI il vantaggio non nasce dall'algoritmo più sofisticato, ma dallo scegliere un problema con dati disponibili, misurare il risultato e tenere la persona dove servono giudizio e responsabilità. Da qui puoi proseguire con il deep learning per capire i modelli più potenti, oppure con gli LLM per vedere come questi principi arrivano fino a ChatGPT.
L'AI diventa utile quando entra nei processi. Giallo Studio aiuta PMI e team a costruire automazioni concrete, misurabili e sostenibili — e puoi vedere gli esperimenti applicati nel The Lab.
Risorse correlate
FAQ
Che cos'è il machine learning in parole semplici?
Il machine learning (apprendimento automatico) è un metodo che permette a un software di imparare a svolgere un compito dagli esempi, invece di seguire regole scritte a mano da un programmatore. Si mostrano al sistema molti casi già risolti e lui ricava da solo gli schemi per gestire casi nuovi.
Qual è la differenza tra machine learning e intelligenza artificiale?
L'intelligenza artificiale è l'obiettivo generale: far svolgere a una macchina compiti 'intelligenti'. Il machine learning è il metodo più usato oggi per ottenerlo, cioè far imparare il software dai dati. Tutto il machine learning è AI, ma non tutta l'AI usa il machine learning.
Quali sono i tipi di machine learning?
I tre principali sono: apprendimento supervisionato (impara da esempi già etichettati, es. email spam/non spam), non supervisionato (trova gruppi e schemi senza etichette, es. segmentazione clienti) e per rinforzo (impara per tentativi ed errori con premi e penalità, es. robotica e ottimizzazione).
Il machine learning serve solo alle grandi aziende?
No. Le PMI usano il machine learning soprattutto tramite strumenti già pronti: previsione delle vendite, classificazione automatica di email e documenti, rilevamento frodi, raccomandazioni prodotto. Non serve un team di data scientist per partire, ma scegliere un problema con dati disponibili e un risultato misurabile.
Che differenza c'è tra machine learning e deep learning?
Il deep learning è un sottoinsieme del machine learning che usa reti neurali con molti livelli. È più potente su dati complessi come immagini, audio e linguaggio, ma richiede più dati e più potenza di calcolo. Per molti problemi aziendali tabellari, modelli di machine learning più semplici bastano e sono più trasparenti.
Il machine learning può sbagliare?
Sì. Un modello impara dai dati che riceve: se i dati sono pochi, sporchi o non rappresentativi, le previsioni saranno scadenti o distorte. Inoltre fornisce probabilità, non certezze. Per questo nei processi aziendali serve misurare l'accuratezza e tenere un controllo umano sui casi critici.