Cluster · vector database
Vector database: cosa sono e a cosa servono
Cosa sono i vector database e a cosa servono: ricerca per similarità, ricerca semantica, RAG e raccomandazioni, spiegati semplice con esempi per aziende.
Tempo di lettura: 10 min
Guida operativa · Fondamenta AI

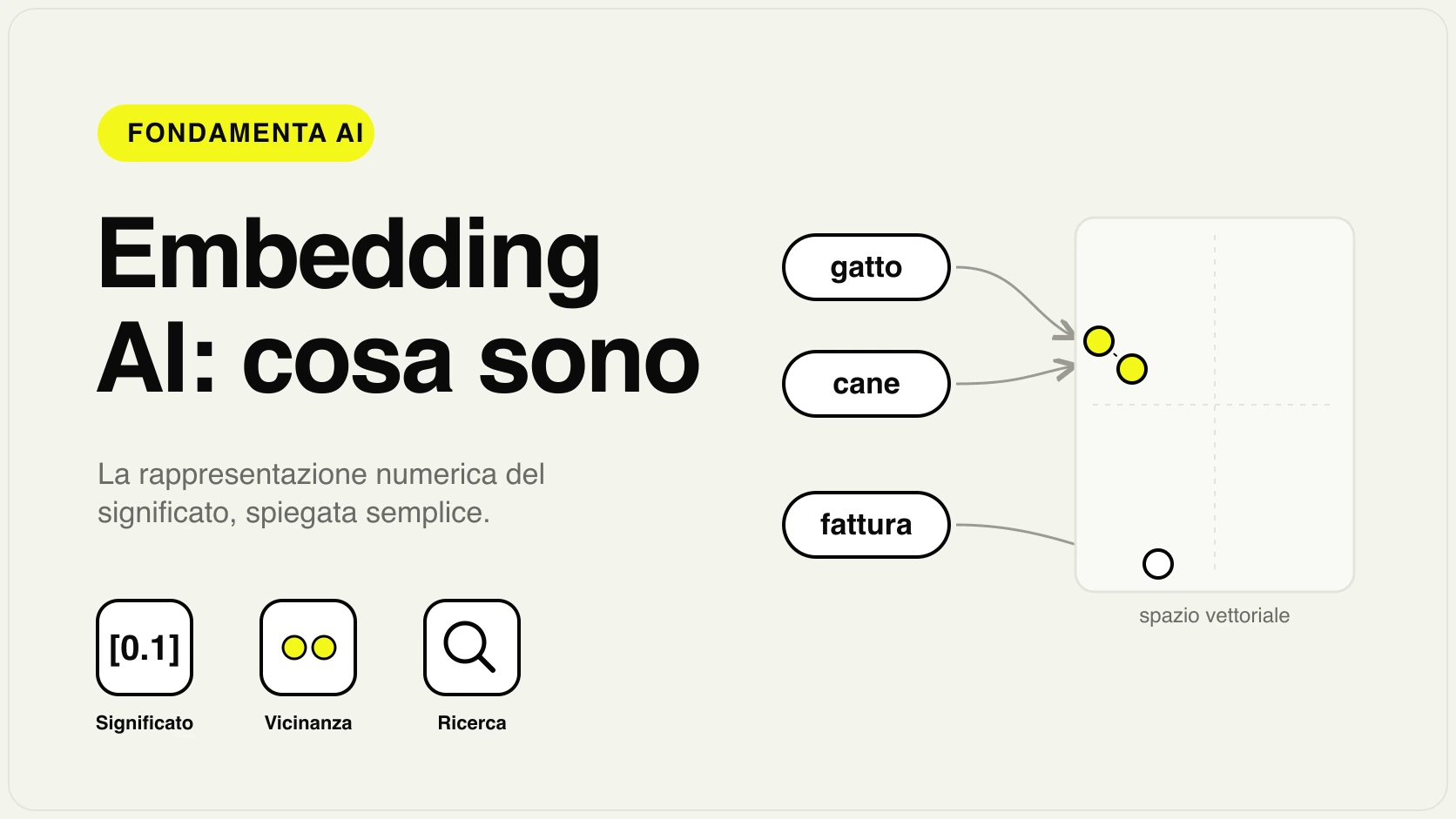
Un vector database (o database vettoriale) è un archivio progettato per memorizzare e cercare vettori: lunghe liste di numeri che rappresentano il significato di un testo, di un'immagine o di un audio. La sua particolarità è il modo in cui cerca: non per parola esatta, ma per similarità. Tu fai una domanda, il sistema la trasforma in un vettore e restituisce gli elementi archiviati che hanno il significato più "vicino", anche quando non contengono nessuna delle parole che hai scritto.
In pratica è il motore che permette di cercare per significato invece che per corrispondenza letterale. È la tecnologia sotto la ricerca semantica, sotto i sistemi che fanno rispondere un'AI sui tuoi documenti (i sistemi RAG) e sotto molti motori di raccomandazione. I vettori, a loro volta, vengono prodotti da un modello di embedding: senza embedding non c'è niente da archiviare.
In questa guida vediamo cos'è davvero un vector database, come funziona la ricerca per similarità, a cosa serve in azienda, quali soluzioni esistono (Pinecone, Weaviate, Qdrant, pgvector) e come scegliere senza farsi guidare dall'hype.
In sintesi
- Un vector database archivia vettori e cerca per similarità: trova i contenuti più vicini per significato, non per parola esatta.
- I vettori arrivano da un modello di embedding; il database li conserva e li confronta velocemente anche su milioni di elementi.
- Serve per ricerca semantica, sistemi RAG (far rispondere un'AI sui tuoi documenti) e raccomandazioni.
- Esistono motori dedicati (Pinecone, Weaviate, Qdrant) ed estensioni su database esistenti (pgvector per PostgreSQL): nessuno è "il migliore" in assoluto.
- Spesso la soluzione più solida è ibrida: parole chiave per i filtri esatti, vettori per il significato.
- Il vector database è un pezzo del sistema: la qualità dipende soprattutto da dati, preparazione e modello di embedding.
Cos'è un vector database
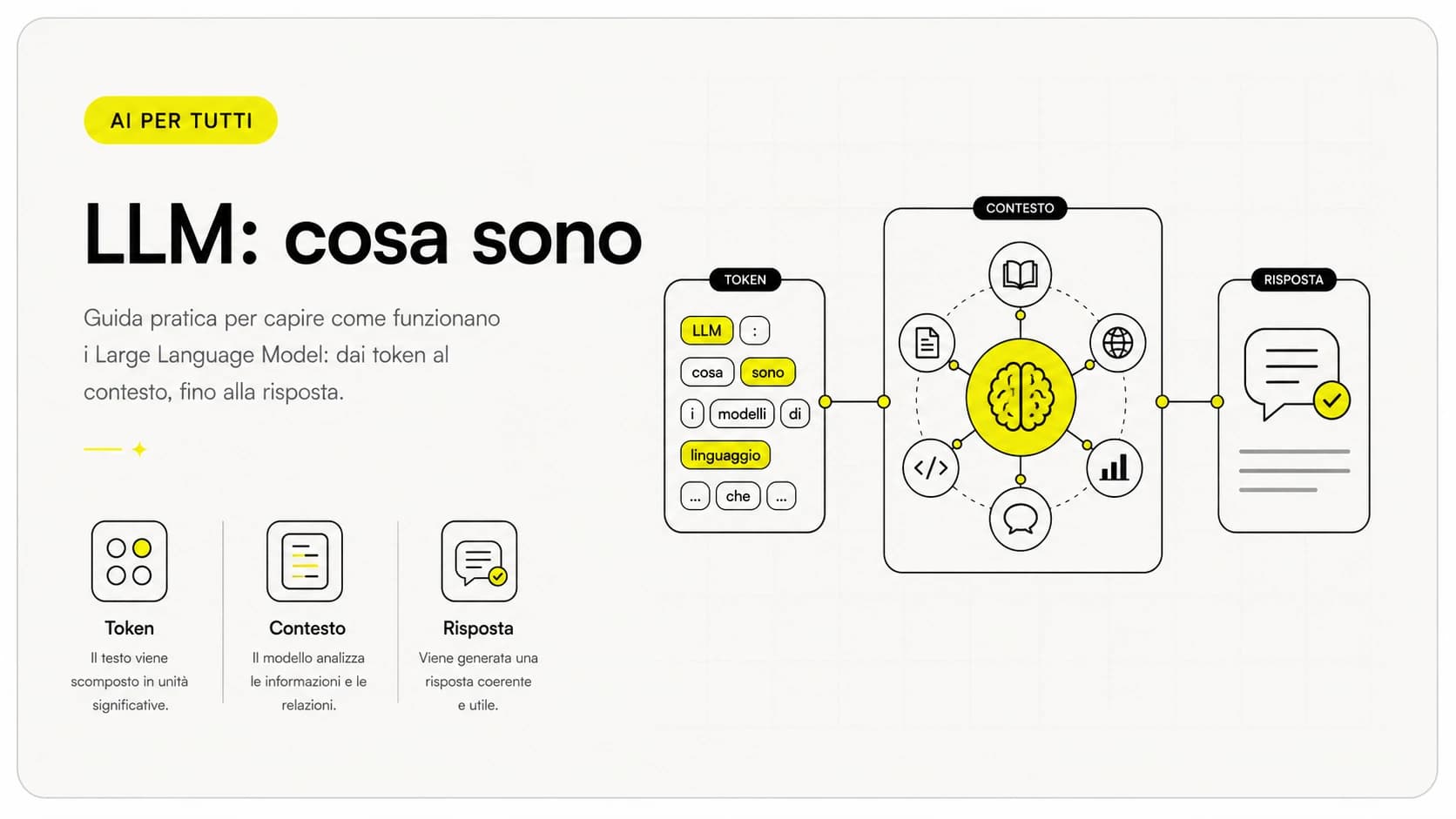
Per capire un vector database bisogna prima capire cosa archivia. Quando un modello AI "legge" un testo, lo trasforma in un vettore: una lista di centinaia o migliaia di numeri (per esempio 384, 768 o 1.536 valori) che ne cattura il significato. Testi con significato simile producono vettori vicini tra loro; testi molto diversi producono vettori lontani. Questo processo si chiama embedding ed è spiegato in dettaglio nella guida sugli embedding AI.
Un vector database è quindi l'archivio che conserva tutti questi vettori e sa rispondere a una domanda precisa: "dato questo vettore, quali sono i N più simili che ho in memoria?". Lo fa in modo efficiente anche su milioni di elementi, dove un confronto "uno a uno" sarebbe troppo lento.
La differenza con un database tradizionale è netta. Un database classico (un gestionale, un CRM) eccelle nelle domande esatte: "clienti con fatturato superiore a 50.000 €", "ordini di marzo". Un vector database eccelle in una domanda diversa: "i tre documenti più affini al concetto di 'rimborso spese per trasferta'", anche se in quei documenti la frase esatta non compare mai.
Come funziona la ricerca per similarità
La ricerca per similarità è il cuore di tutto. Vale la pena vederla come flusso, perché chiarisce dove sta davvero il lavoro.
- Indicizzazione. I tuoi contenuti (documenti, schede prodotto, FAQ) vengono divisi in pezzi e trasformati in vettori da un modello di embedding. Ogni vettore viene salvato nel database insieme a un riferimento al testo originale.
- Domanda. Quando un utente fa una richiesta, anche la domanda viene trasformata nello stesso tipo di vettore.
- Confronto. Il database misura la "distanza" tra il vettore della domanda e quelli archiviati (di solito con la similarità del coseno o la distanza euclidea) e ordina gli elementi dal più vicino al più lontano.
- Risultati. Restituisce i primi N elementi più simili. Sono i contenuti più rilevanti per significato, non per parole in comune.
Il dettaglio tecnico che conta: su grandi volumi non si confronta la domanda con tutti i vettori uno per uno (sarebbe lento). Si usano algoritmi di ricerca approssimata (il più diffuso si chiama HNSW) che trovano i vicini "quasi migliori" molto più in fretta, accettando un margine minimo di imprecisione in cambio di velocità. Per chi usa il sistema il risultato è semplice: cerco "come faccio a chiedere le ferie?" e ottengo il paragrafo giusto del regolamento, anche se lì dentro si parla di "richiesta di congedo".
A cosa serve un vector database
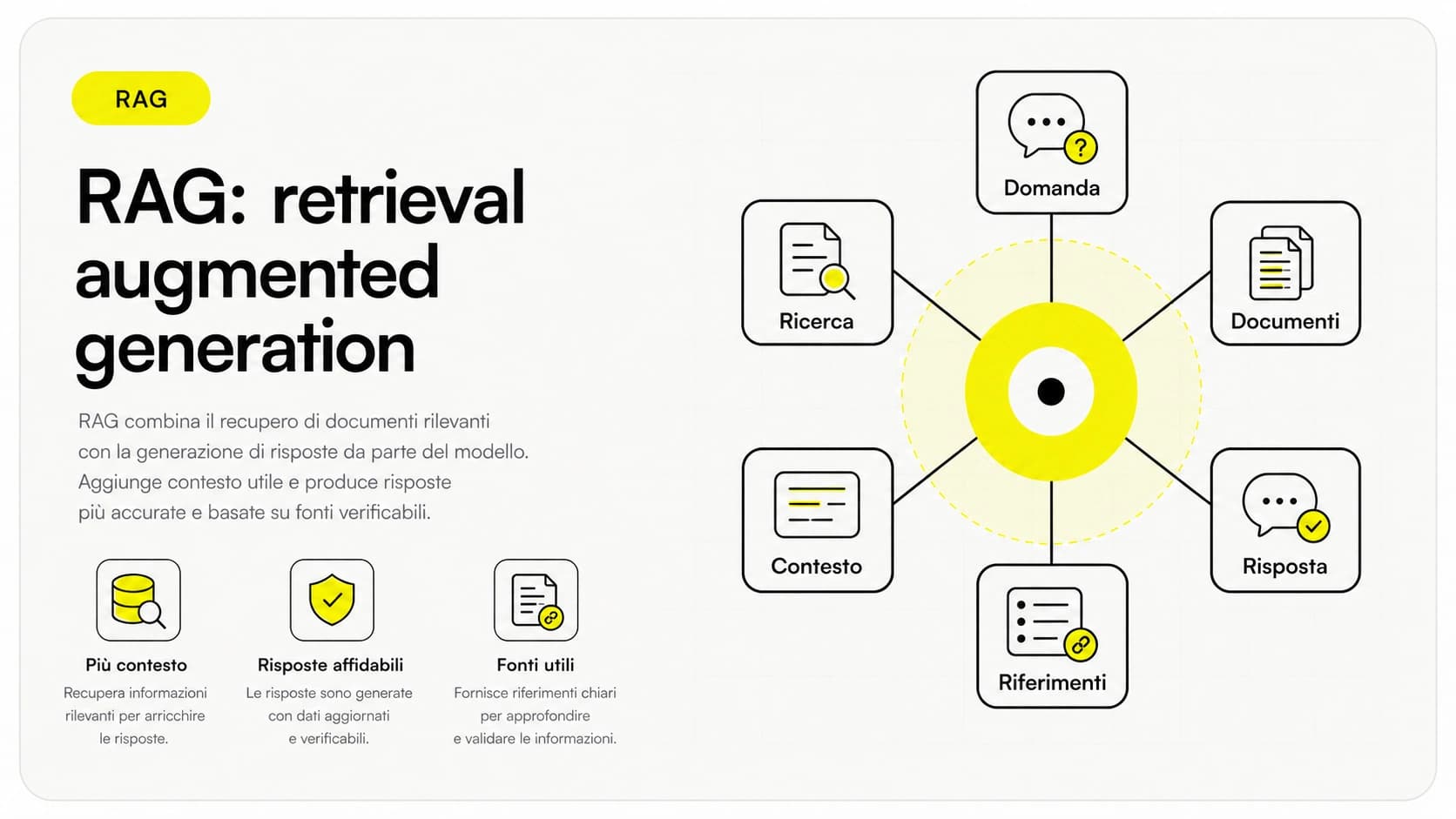
Qui sta il punto pratico. Un vector database non è interessante in sé: è interessante per le cose che abilita. Le tre famiglie d'uso più solide sono ricerca semantica, RAG e raccomandazioni.
| Caso d'uso | Cosa risolve | Esempio concreto | Quando preferirlo |
|---|---|---|---|
| Ricerca semantica | Trovare contenuti per significato, non per parola esatta | Cercare nel manuale interno "blocco macchina linea 2" e ottenere la procedura giusta anche se titolata diversamente | Knowledge base, intranet, cataloghi con descrizioni in linguaggio libero |
| RAG (risposte sui tuoi dati) | Dare a un LLM i documenti giusti prima di rispondere | Assistente che risponde sulle policy aziendali citando il documento di origine | Assistenti interni, supporto clienti su FAQ e contratti |
| Raccomandazioni | Suggerire elementi simili a uno di riferimento | "Prodotti correlati" per significato, non solo per categoria | E-commerce, contenuti, matching domanda/offerta |
| Deduplicazione e clustering | Raggruppare contenuti affini, scovare i quasi-duplicati | Trovare ticket di assistenza che parlano dello stesso problema scritto in modi diversi | Pulizia dati, analisi recensioni, supporto |
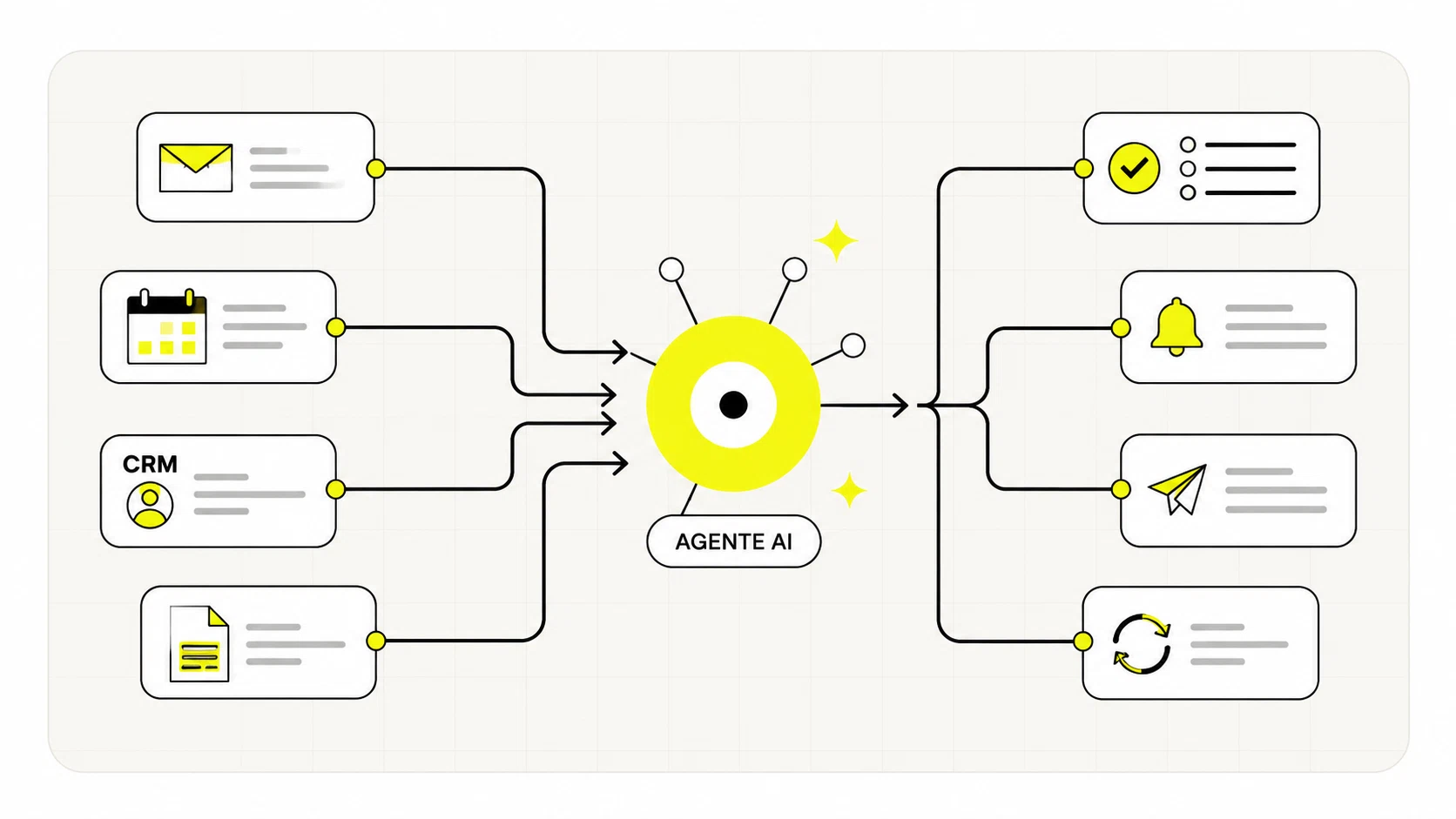
Il caso più richiesto oggi è il RAG: invece di affidarti alla memoria generica di un modello (che non conosce la tua azienda e può inventare risposte), recuperi prima i passaggi più rilevanti dei tuoi documenti con il vector database, poi li passi al modello come contesto. Il modello risponde restando ancorato ai tuoi dati. È esattamente il meccanismo descritto nella guida su cos'è il RAG, e il vector database ne è il motore di recupero. Lo stesso recupero alimenta spesso gli agenti AI, che oltre a rispondere compiono azioni nei tuoi sistemi.
Quali soluzioni di vector database esistono
Le opzioni si dividono in due grandi categorie: estensioni di database che hai già e motori dedicati. Nessuna è "la migliore" in assoluto — dipende da dove vivono i tuoi dati, dai volumi e dalle competenze interne.
Estensione su DB esistente
- pgvector: estensione per PostgreSQL. Se usi già Postgres, aggiungi la ricerca vettoriale senza un sistema in più.
- Meno componenti da gestire, vettori e dati relazionali nello stesso posto.
- Ottimo per volumi piccoli e medi e per chi vuole partire semplice.
Motore dedicato
- Qdrant, Weaviate: motori open source nati per i vettori, anche self-hosted.
- Pinecone: servizio gestito (managed), riduce il lavoro di infrastruttura.
- Convengono su grandi volumi, alta concorrenza o filtri/ricerca avanzati.
Una regola pratica utile: se usi già PostgreSQL e i volumi sono contenuti, parti da pgvector. Eviti di introdurre un sistema separato e tieni tutto nello stesso database. Quando i volumi crescono, le richieste si moltiplicano o servono funzionalità di ricerca più sofisticate, valuti un motore dedicato. Cambiare dopo è possibile: l'importante è non sovradimensionare al primo giorno.
Quali criteri usare per scegliere davvero?
Valuta sempre sul caso concreto, non sulla popolarità del nome. I criteri che contano di più: dove sono già i tuoi dati (se sono in Postgres, pgvector parte avvantaggiato), il volume di vettori previsto, i costi totali (licenze, infrastruttura, ore di gestione), la necessità o meno di un servizio gestito rispetto a un self-hosting, i vincoli di privacy (dati in UE, GDPR) e le competenze interne disponibili. Un servizio gestito costa di più in licenza ma meno in lavoro; un open source self-hosted è il contrario. Per dati personali, verifica sempre dove vengono ospitati e processati.
Esempi pratici
Due scenari realistici di PMI e professionisti italiani, per rendere concreto il discorso.
1. Studio di consulenza — assistente sui documenti interni. Lo studio ha anni di circolari, normative e modelli sparsi in cartelle e PDF. Trovare la risposta giusta richiede tempo e dipende da chi "si ricorda dove sta". Con un sistema RAG, i documenti vengono trasformati in vettori e archiviati in un vector database (qui basta pgvector, i volumi sono contenuti). Un collaboratore chiede in linguaggio naturale "quale aliquota si applica in questo caso?" e l'assistente recupera i passaggi rilevanti e risponde citando il documento di origine. Il valore non è "l'AI sa le risposte", ma "l'AI trova in fretta il pezzo giusto dei tuoi documenti".
2. E-commerce — ricerca e prodotti correlati. Un catalogo di migliaia di articoli con descrizioni libere. La ricerca per parole chiave fallisce quando il cliente usa termini diversi da quelli della scheda ("scarpe da corsa" contro "running"). Trasformando le descrizioni in vettori, la ricerca semantica trova i prodotti giusti per significato, e lo stesso meccanismo alimenta i "prodotti correlati" calcolati sulla somiglianza reale, non solo sulla categoria. Qui, con volumi e traffico alti, può avere senso un motore dedicato come Qdrant o un servizio gestito. La scelta si fa sui numeri (volumi, query al secondo, budget), non sul nome più di moda.
In entrambi i casi il vector database non lavora da solo: serve un modello di embedding per creare i vettori, una preparazione attenta dei documenti e, nel caso del RAG, un LLM che genera la risposta finale. È un ingranaggio di un sistema, non una scatola magica.
Errori da evitare
- Credere che il vector database "capisca" i documenti. Non capisce niente: conserva e confronta vettori. L'intelligenza sta nel modello di embedding e nella preparazione dei dati. Se i vettori sono fatti male, la ricerca sarà mediocre per quanto buono sia il database.
- Introdurlo senza averne bisogno. Se ti servono filtri esatti su codici, date e importi, la ricerca tradizionale basta ed è più semplice. Il vector database serve quando cerchi per significato su testo libero. Non aggiungerlo "perché lo usano tutti".
- Scartare la ricerca ibrida. Spesso il risultato migliore non è solo-vettori, ma parole chiave più similarità: i filtri esatti (cliente, data, categoria) restringono il campo, i vettori ordinano per rilevanza semantica. Ignorare l'ibrido peggiora la qualità.
- Sovradimensionare al primo giorno. Partire con un motore complesso e gestito quando bastava pgvector aggiunge costi e lavoro inutili. Parti dal minimo che funziona, cresci quando i numeri lo chiedono.
- Dimenticare l'aggiornamento dei dati. I documenti cambiano. Se non aggiorni i vettori quando aggiorni i contenuti, il sistema risponde con informazioni vecchie. La pipeline di indicizzazione va mantenuta, non è "una volta e basta".
Come applicarlo in azienda
Introdurre un vector database in modo sensato significa partire dal problema, non dalla tecnologia. Il percorso è breve e ripetibile.
- Parti da una domanda reale: "i nostri documenti sono difficili da cercare" o "il supporto risponde sempre alle stesse cose". Il vector database serve a questo, non a "avere l'AI".
- Prepara i dati prima del database: raccogli i documenti, dividili in pezzi sensati, togli il rumore. È qui che si gioca l'80% della qualità.
- Scegli un modello di embedding adatto: alla lingua (italiano), al dominio e ai vincoli di privacy. I vettori dipendono da questa scelta.
- Inizia dal minimo: pgvector se usi già PostgreSQL e i volumi sono contenuti. Un motore dedicato solo quando i numeri lo giustificano.
- Misura la qualità delle risposte: il sistema trova davvero il documento giusto? Le persone si fidano? Senza una verifica concreta non sai se funziona.
Questo è esattamente il tipo di lavoro che rende utile una consulenza AI: collegare il vector database al resto (embedding, documenti, modello, processi) e capire dove conviene davvero investire. Se l'obiettivo è far rispondere un'AI sui tuoi contenuti, il vector database vive dentro un sistema più ampio — spesso un agente AI o un flusso di automazione dei processi che recupera, ragiona e agisce. E se vuoi vedere prove e prototipi reali, gli esperimenti del The Lab mostrano questi mattoni in azione.
Conclusione
Un vector database è l'archivio che rende possibile la ricerca per similarità: trova i contenuti più vicini per significato invece che per parola esatta. È il motore della ricerca semantica, dei sistemi RAG e delle raccomandazioni, e lavora sempre insieme a un modello di embedding che trasforma testi e immagini in vettori. Le soluzioni non mancano — pgvector, Qdrant, Weaviate, Pinecone — ma nessuna è "la migliore" in assoluto: la scelta giusta dipende da dati, volumi, costi e competenze, e va fatta sul caso concreto. Per il quadro completo su come questi mattoni entrano nei processi, prosegui con la guida AI per aziende.
L'AI diventa utile quando entra nei processi. Giallo Studio aiuta PMI e team a costruire automazioni concrete, misurabili e sostenibili.
Risorse correlate
FAQ
Cos'è un vector database in parole semplici?
Un vector database è un archivio progettato per memorizzare e cercare vettori, cioè liste di numeri che rappresentano il significato di testi, immagini o audio. Invece di cercare parole esatte, trova gli elementi più 'vicini' per significato. È la base tecnica della ricerca semantica e dei sistemi RAG.
Qual è la differenza tra un database tradizionale e un vector database?
Un database tradizionale cerca corrispondenze esatte o per intervalli (codice cliente uguale a X, data tra A e B). Un vector database cerca per similarità: data una domanda, restituisce i contenuti più affini per significato, anche se non contengono le stesse parole. Servono a cose diverse e spesso convivono.
A cosa serve un vector database in azienda?
Serve a far trovare risposte nei documenti aziendali, a costruire assistenti che rispondono sui propri contenuti (RAG), a sistemi di raccomandazione e alla ricerca semantica su cataloghi e knowledge base. In pratica, ogni volta che vuoi cercare 'per significato' e non per parola esatta.
Pinecone, Weaviate, Qdrant o pgvector: quale scegliere?
Non esiste un vincitore assoluto. pgvector conviene se usi già PostgreSQL e i volumi sono contenuti; Qdrant e Weaviate sono motori dedicati open source; Pinecone è un servizio gestito che toglie lavoro di infrastruttura. La scelta dipende da volumi, costi, competenze interne e dove vivono già i tuoi dati. Vanno valutati sul caso concreto.
Un vector database mi serve davvero o basta la ricerca normale?
Se ti basta cercare codici, date e filtri esatti, la ricerca tradizionale è sufficiente e più semplice. Il vector database serve quando hai bisogno di cercare per significato su testo libero, documenti o descrizioni, dove le parole esatte non bastano. Spesso la soluzione migliore è ibrida: parole chiave più similarità.
Un vector database capisce da solo i miei documenti?
No. Il database conserva e confronta vettori, ma i vettori vanno generati da un modello di embedding e i documenti vanno preparati (divisi in pezzi, puliti, aggiornati). Il vector database è un pezzo del sistema, non la soluzione completa: la qualità dipende soprattutto da dati e preparazione.