Cluster · deep learning
Deep learning: cos'è spiegato semplice
Cos'è il deep learning spiegato semplice: come funzionano le reti neurali profonde, differenze con il machine learning, esempi reali e usi in azienda.
Tempo di lettura: 10 min
Guida operativa · Fondamenta AI
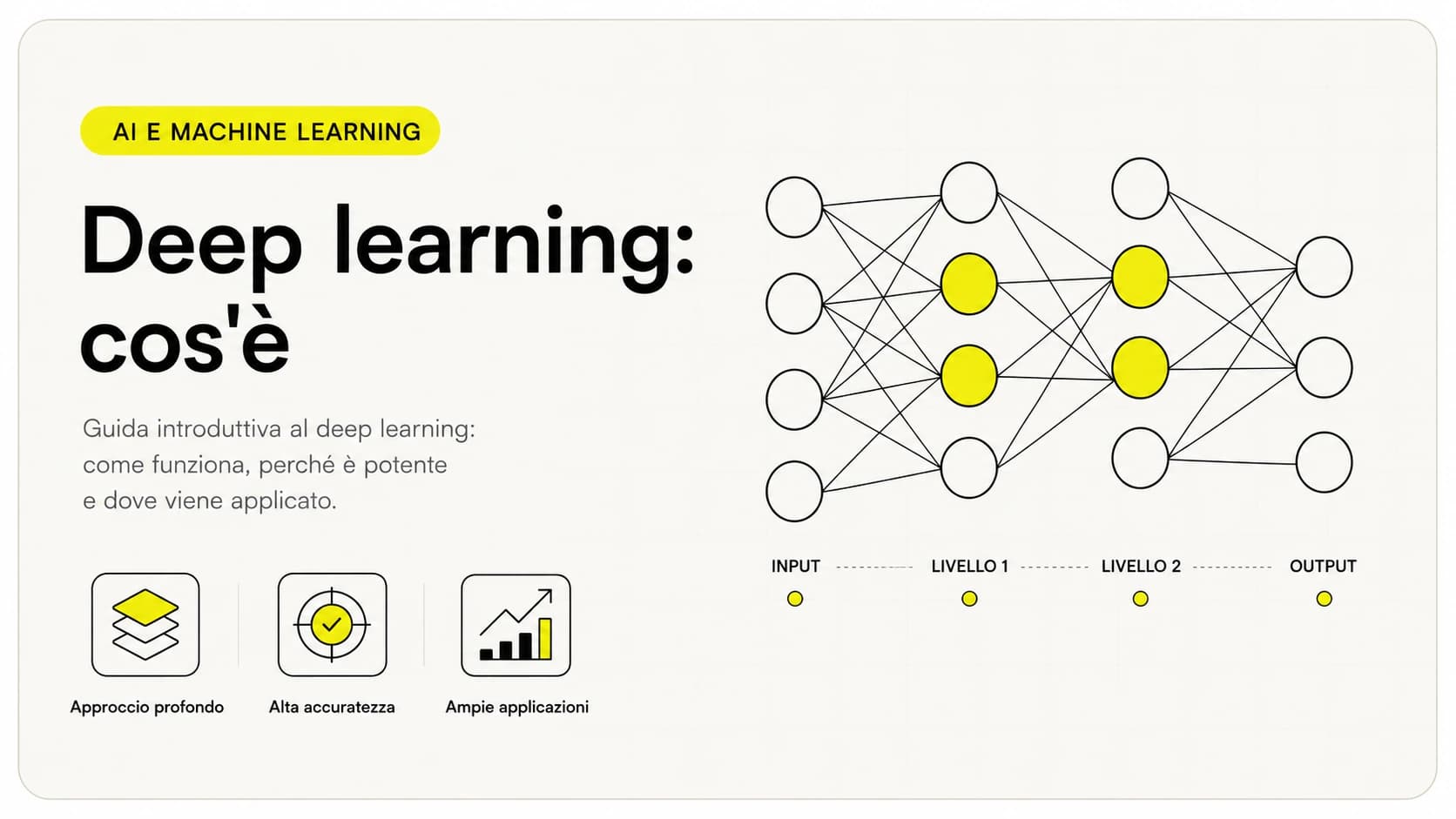
Il deep learning è un tipo di machine learning basato su reti neurali artificiali con molti strati. La parola "deep" (profondo) si riferisce proprio a questo: la presenza di numerosi strati intermedi tra l'ingresso e l'uscita, che permettono al sistema di imparare schemi via via più complessi. È la tecnologia che oggi sta dietro al riconoscimento delle immagini, alla trascrizione vocale e ai modelli linguistici come ChatGPT.
La differenza chiave rispetto al machine learning tradizionale è una sola, ma importante: nel deep learning non è un umano a indicare al sistema quali caratteristiche dei dati guardare. È la rete a scoprirle da sola, strato dopo strato. Questo lo rende molto potente sui dati "grezzi" come immagini, audio e testo, ma anche più affamato di dati e di potenza di calcolo.
In questa guida vediamo cos'è il deep learning spiegato semplice, come funzionano le reti neurali profonde, in cosa si differenzia dal machine learning, quando ha senso usarlo e cosa cambia concretamente per una PMI.
In sintesi
- Il deep learning è un sottoinsieme del machine learning basato su reti neurali con molti strati ("profonde").
- La novità rispetto al machine learning classico: la rete impara da sola quali caratteristiche contano, invece di farsele indicare da un umano.
- Funziona benissimo su dati grezzi e non strutturati: immagini, audio, testo. È la base dei modelli linguistici come ChatGPT.
- In cambio richiede molti più dati e molta più potenza di calcolo rispetto al machine learning tradizionale.
- Una PMI quasi mai addestra reti proprie: usa prodotti già pronti che le contengono, scegliendo il processo giusto da automatizzare.
Cosa significa "deep learning"
Per capire il deep learning conviene partire da come si incastrano i termini. L'intelligenza artificiale è l'obiettivo generale (far svolgere a una macchina compiti "intelligenti"). Il machine learning è il metodo più usato per ottenerlo: far imparare il software dagli esempi invece di programmare ogni regola a mano. Il deep learning è una specializzazione del machine learning, basata su un tipo specifico di modello: la rete neurale profonda.
In altre parole sono tre cerchi concentrici: il deep learning sta dentro il machine learning, che sta dentro l'intelligenza artificiale. Se vuoi il quadro d'insieme, parti dalla guida su cos'è l'intelligenza artificiale; qui ci concentriamo sul cerchio più interno.
La caratteristica che definisce il deep learning è la profondità: la rete ha molti strati intermedi (a volte decine o centinaia). Ogni strato trasforma un po' i dati e li passa al successivo. I primi strati colgono dettagli grezzi, gli ultimi concetti astratti. È questa catena di trasformazioni che permette di gestire dati complessi senza dire alla macchina, passo per passo, cosa cercare.
Come funzionano le reti neurali, passo per passo
Una rete neurale è un modello matematico fatto di tanti piccoli nodi chiamati "neuroni", collegati tra loro e organizzati in strati. Ogni collegamento ha un numero, il peso, che dice quanto quel segnale conta. Addestrare la rete significa regolare tutti questi pesi finché impara a collegare gli input agli output corretti. Vediamolo come flusso.
- Strato di ingresso. I dati entrano già scomposti in numeri: i pixel di un'immagine, i campioni di un audio, le parole di una frase trasformate in vettori (gli embedding).
- Strati nascosti. Sono il cuore "profondo". Ogni strato combina i segnali ricevuti, applica i pesi e passa il risultato al successivo. Strato dopo strato, la rete costruisce rappresentazioni sempre più astratte.
- Strato di uscita. L'ultimo strato produce la risposta: "è un gatto", "questa fattura è del cliente X", "la parola successiva più probabile è...".
- Confronto con la risposta giusta. Durante l'addestramento la rete confronta l'output con quello corretto e misura l'errore.
- Aggiustamento dei pesi. L'errore viene propagato all'indietro (è la backpropagation) e tutti i pesi vengono ritoccati di pochissimo. Ripetendo su milioni di esempi, la rete migliora.
L'idea chiave: imparare le caratteristiche da soli
Qui sta il salto rispetto al machine learning tradizionale. Immagina di voler riconoscere un gatto in una foto. Con un approccio classico, un umano dovrebbe descrivere a mano cosa cercare: "orecchie a punta", "baffi", "forma degli occhi". Lavoro lungo, fragile e quasi impossibile su dati complessi.
Con il deep learning non descrivi niente. Mostri alla rete migliaia di foto etichettate "gatto" / "non gatto" e lei impara da sola quali combinazioni di pixel contano. I primi strati imparano a riconoscere bordi e colori, quelli intermedi forme (un orecchio, un occhio), gli ultimi l'oggetto intero. Nessuno gliel'ha spiegato: è emerso dai dati. Questa capacità di costruire automaticamente le caratteristiche rilevanti è il vero motivo per cui il deep learning ha sbloccato compiti che prima erano irraggiungibili.
Perché serve così tanta potenza di calcolo
Una rete profonda può avere milioni o miliardi di pesi da regolare, e ogni esempio passa avanti e indietro più volte. Questo richiede una quantità enorme di calcoli. La svolta è arrivata con le GPU, processori nati per i videogiochi ma perfetti per le operazioni matematiche parallele del deep learning. È la combinazione di tanti dati, GPU economiche e reti profonde ad aver reso possibile l'AI di oggi, compresi i modelli linguistici che alimentano gli assistenti che usiamo ogni giorno.
Deep learning e machine learning: che differenza c'è
Sono spesso usati come sinonimi, ma non lo sono: il deep learning è una parte del machine learning. La distinzione pratica conta quando devi capire quale approccio serve a un problema reale.
| Criterio | Machine learning classico | Deep learning |
|---|---|---|
| Chi sceglie le caratteristiche | Spesso un umano, a mano | La rete neurale, da sola |
| Tipo di dati ideale | Dati strutturati (tabelle, numeri) | Dati grezzi: immagini, audio, testo |
| Quantità di dati | Anche poche migliaia di esempi | Da molte migliaia a milioni |
| Potenza di calcolo | Modesta, spesso basta un PC | Elevata, di norma servono GPU |
| Trasparenza | Più interpretabile | "Scatola nera": difficile spiegare il perché |
| Esempio tipico | Stima delle vendite da uno storico | Trascrizione vocale, riconoscimento immagini |
La lettura giusta non è "il deep learning è meglio". Per molti problemi aziendali con dati in tabella (prevedere le vendite, stimare il rischio di abbandono di un cliente) un modello di machine learning classico è più semplice, più economico e più trasparente. Il deep learning brilla quando i dati sono grezzi e complessi e quando ne hai in grande quantità.
A cosa serve il deep learning
Il deep learning è ovunque, anche dove non lo vedi. Ecco i campi in cui ha fatto la differenza concreta e che probabilmente già usi in qualche prodotto.
- Visione artificiale: riconoscere oggetti, leggere targhe, controllo qualità su una linea, lettura automatica di documenti scansionati.
- Linguaggio: traduzione automatica, riassunti, classificazione di testi e i grandi modelli linguistici come ChatGPT, Claude e Gemini.
- Audio e voce: trascrizione di riunioni, comandi vocali, sintesi vocale realistica.
- Sistemi di raccomandazione: i suggerimenti di prodotti, video e contenuti che vedi sulle piattaforme più usate.
- AI generativa: generazione di immagini, codice e testo a partire da una richiesta in linguaggio naturale.
Il filo comune è che si tratta quasi sempre di dati non strutturati: foto, suoni, parole. È proprio lì che il deep learning non ha rivali. Per una PMI il punto non è capire l'architettura interna di queste reti, ma sapere che esistono prodotti già pronti che le sfruttano e che si collegano agli strumenti che usi già.
Esempi pratici
Tre scenari realistici di PMI e professionisti italiani, per rendere concreto dove il deep learning entra nel lavoro di tutti i giorni — quasi sempre attraverso strumenti già pronti, non reti costruite in casa.
1. Officina meccanica — lettura dei documenti del ricambista. Ogni settimana arrivano bolle e DDT cartacei o in PDF scansionato. Uno strumento basato su deep learning (riconoscimento immagini + lettura del testo, l'OCR moderno) legge il documento, estrae codice ricambio, quantità e prezzo, e li riversa nel gestionale. Il titolare controlla solo i casi dubbi. Risultato tipico: meno digitazione manuale, meno errori di trascrizione.
2. Studio di consulenza — trascrizione delle riunioni. Dopo ogni incontro con il cliente serviva mezz'ora per scrivere il verbale. Uno strumento di trascrizione vocale (deep learning sull'audio) produce il testo completo della riunione in pochi minuti; un modello linguistico ne ricava un riassunto con i punti d'azione. Il consulente rilegge e corregge, invece di scrivere da zero.
3. E-commerce di abbigliamento — ricerca per immagine e raccomandazioni. Il cliente carica la foto di un capo che gli piace e il sito propone gli articoli più simili a catalogo (visione artificiale). In parallelo, un sistema di raccomandazione suggerisce prodotti correlati. Sotto entrambe le funzioni c'è deep learning, ma per il negoziante è semplicemente una funzione attivata nella piattaforma.
In tutti e tre i casi nessuno ha "fatto deep learning": hanno scelto un prodotto che lo usa e l'hanno collegato al proprio processo. È il modello che funziona per una PMI.
Quando ha senso (e quando no)
Quando il deep learning conviene
- I dati sono grezzi e non strutturati: immagini, audio, testo libero.
- Ne hai in grande quantità (o usi un modello già addestrato su grandi dataset).
- Il compito è troppo complesso per scrivere regole a mano.
- Puoi tollerare un margine di errore con una revisione umana sui punti critici.
Quando preferire altro
- I dati sono in tabella e gli esempi pochi: meglio il machine learning classico.
- Ti serve poter spiegare perché il modello ha deciso così.
- Il budget di calcolo e dati è limitato e il problema è semplice.
- Bastano poche regole chiare: a volte non serve nemmeno l'AI.
Regola pratica per una PMI: non parti scegliendo "deep learning sì o no", parti dal problema. Definito il processo da alleggerire, nella stragrande maggioranza dei casi esiste già un prodotto che, sotto, usa deep learning. La domanda giusta è "quale strumento risolve questo problema?", non "voglio una rete neurale".
Ma allora una PMI deve mai addestrare una rete propria?
Raramente, e quasi mai da zero. Costruire una rete profonda da zero richiede grandi dataset etichettati, competenze specialistiche e infrastruttura. Nella pratica si parte da un modello già addestrato e, al massimo, lo si adatta ai propri dati (è il caso degli embedding o del fine-tuning). Per la maggior parte delle aziende la scelta sensata è usare strumenti pronti e concentrare le energie sul processo, non sul modello.
Errori da evitare
- Confondere "profondo" con "migliore". Su dati tabellari e con pochi esempi, un modello di machine learning classico spesso vince e costa molto meno. La profondità non è una medaglia.
- Pensare di doverlo costruire in casa. Quasi nessuna PMI ha i dati e l'infrastruttura per addestrare reti da zero. La via giusta è partire da modelli già pronti.
- Trattare l'output come verità. Una rete profonda è una "scatola nera" che restituisce la risposta più probabile, non quella verificata. Su numeri, norme e dati clienti serve sempre un controllo. Vedi le allucinazioni AI.
- Sottovalutare i dati. Senza dati di qualità e in quantità sufficiente, il deep learning non funziona. "Garbage in, garbage out" qui vale doppio.
- Dare in pasto dati sensibili senza criterio. Caricare dati personali dei clienti in strumenti pubblici può violare il GDPR. Servono regole su cosa si può condividere e cosa no.
Come applicarlo in azienda
Per una PMI il deep learning non è un progetto da avviare, ma una tecnologia che entra in casa attraverso strumenti concreti. Il percorso sensato è lo stesso di qualsiasi automazione utile.
- Parti dal processo, non dalla tecnologia. Quale attività ripetitiva su immagini, audio o testo ruba più tempo? Lì il deep learning, dentro un prodotto, può aiutare.
- Misura il punto di partenza. Quante ore, quanti errori, quanti documenti al giorno oggi. Senza numeri non c'è ritorno da valutare.
- Scegli lo strumento minimo già pronto. Un servizio di lettura documenti, di trascrizione o un assistente collegato ai tuoi software. Non un modello su misura.
- Tieni l'umano nel controllo. Il deep learning prepara, la persona approva — soprattutto sui punti che contano.
- Misura di nuovo e decidi. Se i numeri migliorano, estendi; se no, cambia approccio.
Questo è esattamente il tipo di valutazione per cui esiste una consulenza AI: capire quale tecnologia serve davvero a un processo ed evitare di investire in qualcosa di sproporzionato. Spesso il risultato concreto non è "una rete neurale", ma un'automazione di processo collegata agli strumenti che usi già; se vuoi vedere come questi mattoni diventano flussi reali, parti dai servizi di Giallo Studio o dagli esperimenti del The Lab.
Conclusione
Il deep learning non è magia: è machine learning portato in profondità, con reti neurali a molti strati che imparano da sole a riconoscere schemi nei dati grezzi. È la tecnologia che ha reso possibile il riconoscimento di immagini, la trascrizione vocale e i modelli linguistici di oggi. Ma "profondo" non vuol dire sempre "meglio": su molti problemi aziendali con dati in tabella, un modello classico è più semplice, più economico e più trasparente. Per una PMI il valore non sta nel costruire reti, ma nello scegliere il processo giusto e lo strumento pronto che lo risolve. Da qui puoi proseguire con i modelli linguistici e con il machine learning, i due mattoni più vicini al lavoro quotidiano.
L'AI diventa utile quando entra nei processi. Giallo Studio aiuta PMI e team a costruire automazioni concrete, misurabili e sostenibili.
Risorse correlate
FAQ
Che cos'è il deep learning in parole semplici?
Il deep learning è un tipo di machine learning basato su reti neurali artificiali con molti strati. Invece di farsi indicare da un umano quali caratteristiche guardare, il sistema impara da solo a riconoscere schemi sempre più complessi mano a mano che i dati attraversano gli strati: dai dettagli grezzi (bordi, suoni) fino ai concetti astratti (un volto, una frase).
Qual è la differenza tra deep learning e machine learning?
Il deep learning è una parte del machine learning. Nel machine learning classico spesso è un umano a decidere quali caratteristiche dei dati contano; nel deep learning è la rete neurale profonda a trovarle da sola. In cambio il deep learning richiede molti più dati e molta più potenza di calcolo.
Cosa sono le reti neurali?
Una rete neurale è un modello matematico ispirato in modo molto semplificato al cervello: tanti piccoli nodi (neuroni) collegati tra loro, organizzati in strati. Ogni connessione ha un peso che viene regolato durante l'addestramento finché la rete impara a collegare gli input agli output corretti. 'Profonda' significa che ha molti strati intermedi.
Il deep learning serve a una piccola azienda?
Quasi sempre in modo indiretto. Una PMI raramente addestra reti neurali da zero, ma usa ogni giorno prodotti che le contengono: riconoscimento di documenti, trascrizione vocale, assistenti come ChatGPT. Il valore non sta nel costruire il modello, ma nello scegliere il processo giusto da automatizzare con strumenti già pronti.
Quanti dati servono per il deep learning?
Molti più che nel machine learning tradizionale, di solito da migliaia a milioni di esempi. È uno dei motivi per cui le PMI non addestrano reti proprie da zero: conviene partire da modelli già addestrati su grandi dataset e, al massimo, adattarli ai propri dati.
Il deep learning può sbagliare?
Sì. Una rete profonda restituisce la risposta statisticamente più probabile, non quella certamente vera: può sbagliare su casi rari, riflettere i bias dei dati di addestramento o dare un risultato con sicurezza pur essendo errato. Per questo nei processi aziendali serve una revisione umana sui punti critici.