Cluster · AI multimodale
AI multimodale: cos'è e come funziona
Cos'è l'AI multimodale e come funziona, spiegata semplice: testo, immagini, audio e video in un unico modello, esempi reali per PMI, limiti e usi pratici.
Tempo di lettura: 9 min
Guida operativa · Fondamenta AI
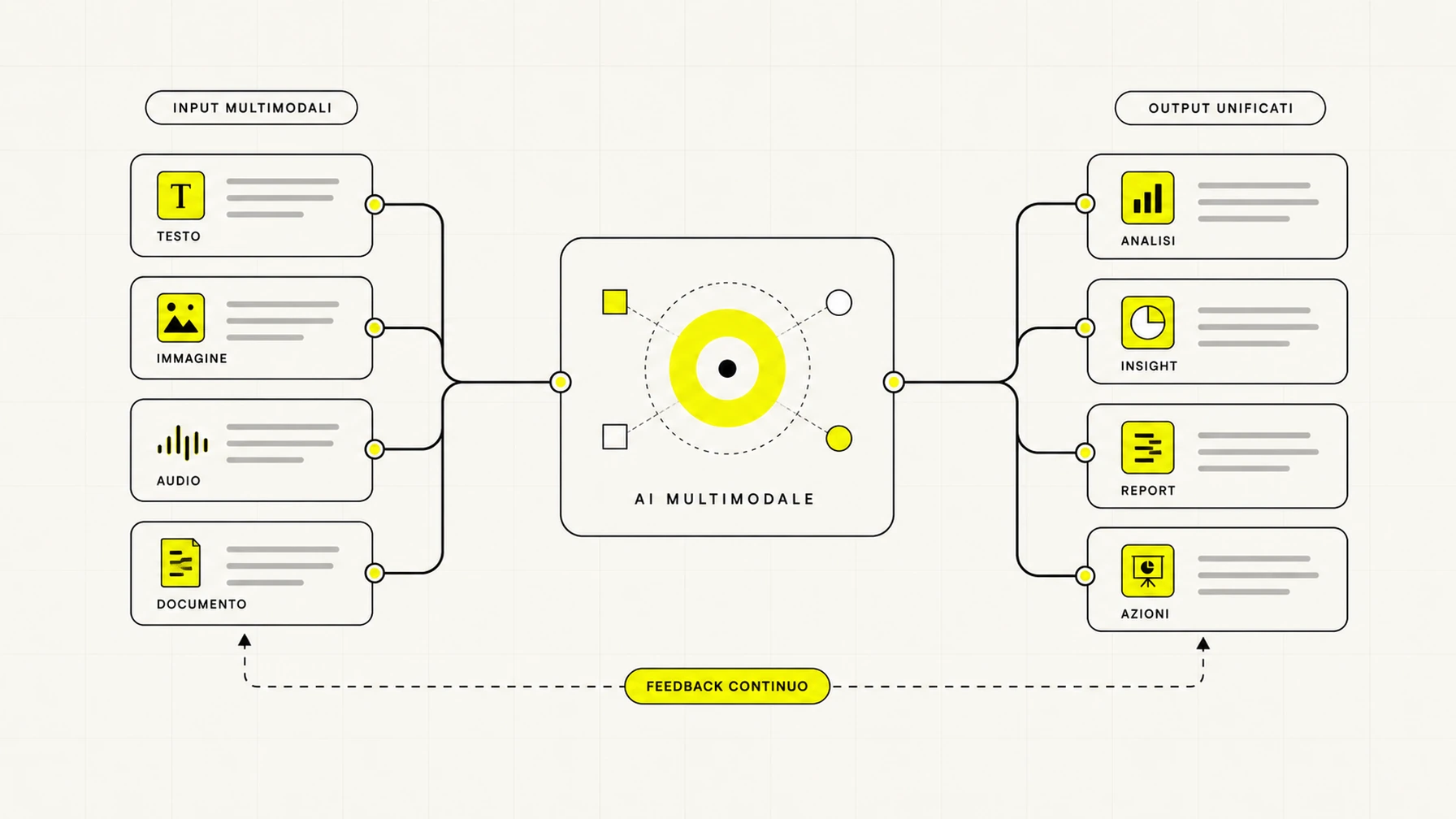
L'AI multimodale è un tipo di intelligenza artificiale capace di capire e combinare più tipi di dato nello stesso sistema: testo, immagini, audio e a volte video. Invece di leggere solo parole, un modello multimodale può guardare una foto, ascoltare una registrazione e leggere un documento, mettendo insieme le informazioni per rispondere a una sola richiesta. In pratica è l'estensione naturale dei modelli linguistici: la stessa tecnologia, ma con più "sensi".
La differenza con un chatbot tradizionale è semplice da intuire. Un chatbot di solo testo capisce e produce solo parole; un modello multimodale capisce anche un'immagine fotografata, un PDF allegato o un messaggio vocale, e può collegarli tra loro. Puoi mostrargli la foto di una bolletta e chiedere "quanto pago e quando scade", oppure passargli la registrazione di una riunione e farti scrivere il riassunto. Tutto dentro la stessa conversazione.
In questa guida vediamo cos'è davvero l'AI multimodale, come funziona dietro le quinte, cosa cambia per una PMI, dove conviene usarla e quali sono i suoi limiti concreti.
In sintesi
- L'AI multimodale elabora più tipi di dato nello stesso modello: testo, immagini, audio e a volte video, invece di gestirli con strumenti separati.
- Dietro c'è la stessa idea dei modelli linguistici: ogni input (anche una foto o un audio) viene tradotto in una rappresentazione numerica comune che il modello sa confrontare.
- Per una PMI il vantaggio è pratico: meno passaggi tra strumenti diversi, perché un solo sistema legge il documento, descrive l'immagine o trascrive la voce.
- I principali assistenti (ChatGPT, Claude, Gemini) sono già multimodali: spesso non serve nulla di nuovo, basta usare bene quello che esiste.
- Resta un'AI statistica: può sbagliare a leggere numeri, dettagli o audio disturbati, quindi sui dati critici serve sempre un controllo umano.
Cosa significa "multimodale"
In gergo AI, una modalità è un tipo di dato: il testo è una modalità, le immagini un'altra, l'audio un'altra ancora, e così video, tabelle o segnali da sensori. Un modello unimodale lavora con una sola di queste (per esempio solo testo); un modello multimodale ne combina due o più.
La parola chiave è combinare, non solo accettare. Un sistema davvero multimodale non si limita a ricevere un'immagine e poi un testo come due richieste scollegate: li ragiona insieme. Se gli mostri la foto di uno scaffale e chiedi "quali prodotti mancano rispetto a questa lista", deve mettere in relazione ciò che vede con ciò che legge. È questo legame tra modalità diverse a renderlo utile.
Una distinzione che torna spesso è tra input e output:
- Input multimodale: il modello riceve più formati (gli dai una foto + una domanda scritta). È la capacità più diffusa e quella più utile in azienda oggi.
- Output multimodale: il modello produce più formati (genera testo ma anche un'immagine o un audio). È in forte crescita, ma molti casi aziendali si risolvono già con il solo input multimodale.
Quando un fornitore dice "il nostro modello è multimodale", chiedi sempre quali modalità accetta in ingresso e quali produce in uscita: la differenza cambia cosa puoi farci davvero.
Come funziona l'AI multimodale, passo per passo
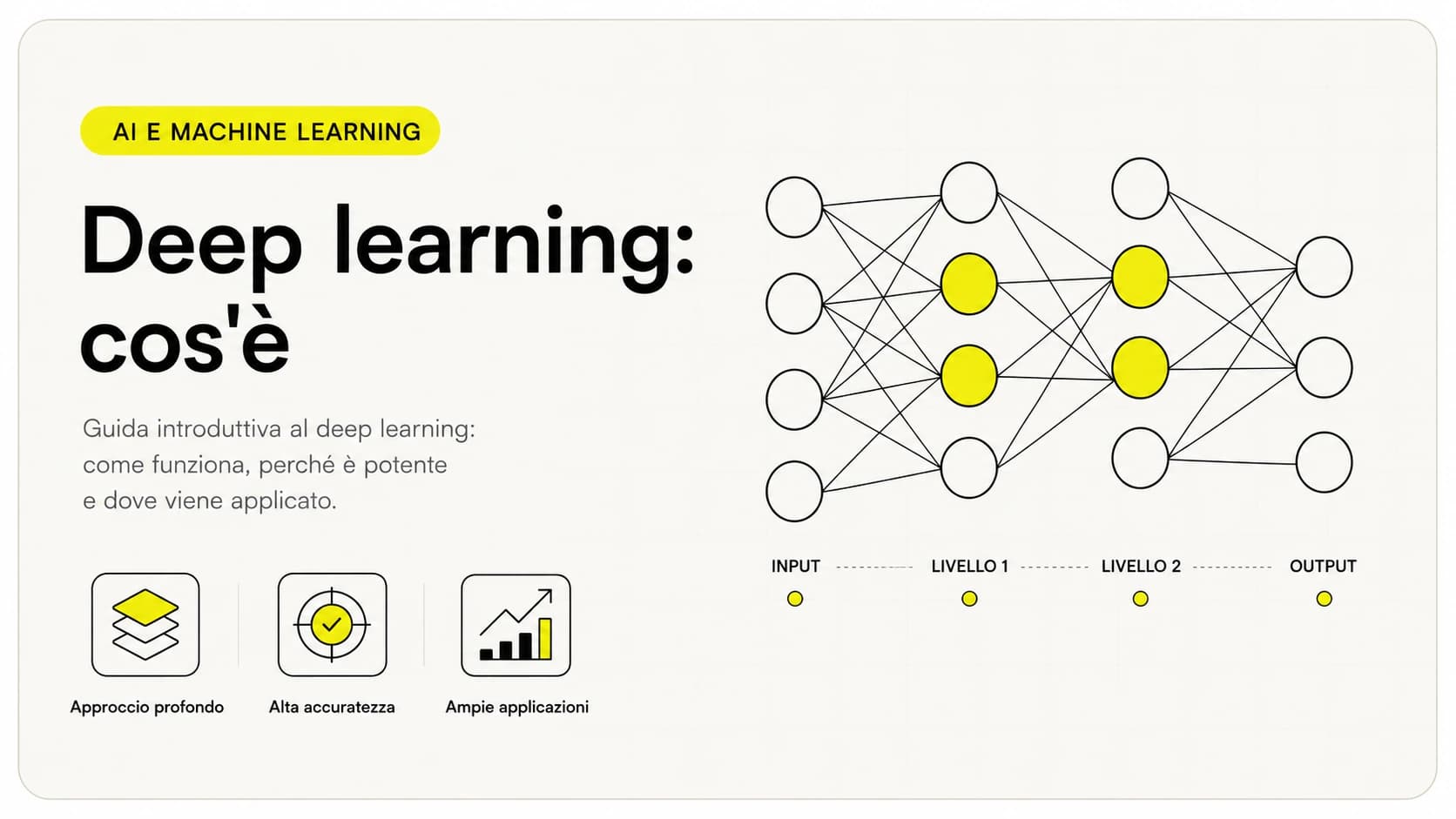
Il meccanismo è più semplice di quanto sembri e parte da un'idea già vista nel deep learning: trasformare qualsiasi cosa in numeri. Una frase, un'immagine e un suono sono dati molto diversi per noi, ma il modello li riporta tutti allo stesso "linguaggio" matematico, così può confrontarli.
- Codifica di ogni modalità. Ogni tipo di dato passa per un encoder dedicato: uno per il testo, uno per le immagini, uno per l'audio. Ognuno trasforma il suo input in una sequenza di numeri (una rappresentazione vettoriale).
- Spazio comune. Le diverse rappresentazioni vengono portate in uno spazio condiviso, dove un concetto simile — la parola "gatto", la foto di un gatto, il miagolio — finisce in posizioni vicine. È qui che le modalità "si parlano".
- Fusione. Il modello combina le rappresentazioni per ragionare su tutto insieme: lega la domanda scritta a ciò che ha "visto" nell'immagine o "sentito" nell'audio.
- Generazione della risposta. Dalla rappresentazione fusa il modello produce l'output più probabile, di solito testo: una risposta, un riassunto, una classificazione.
- Controllo umano. Come per ogni AI, il risultato va verificato dove conta — soprattutto su numeri, nomi e dati estratti da un'immagine o da un audio.
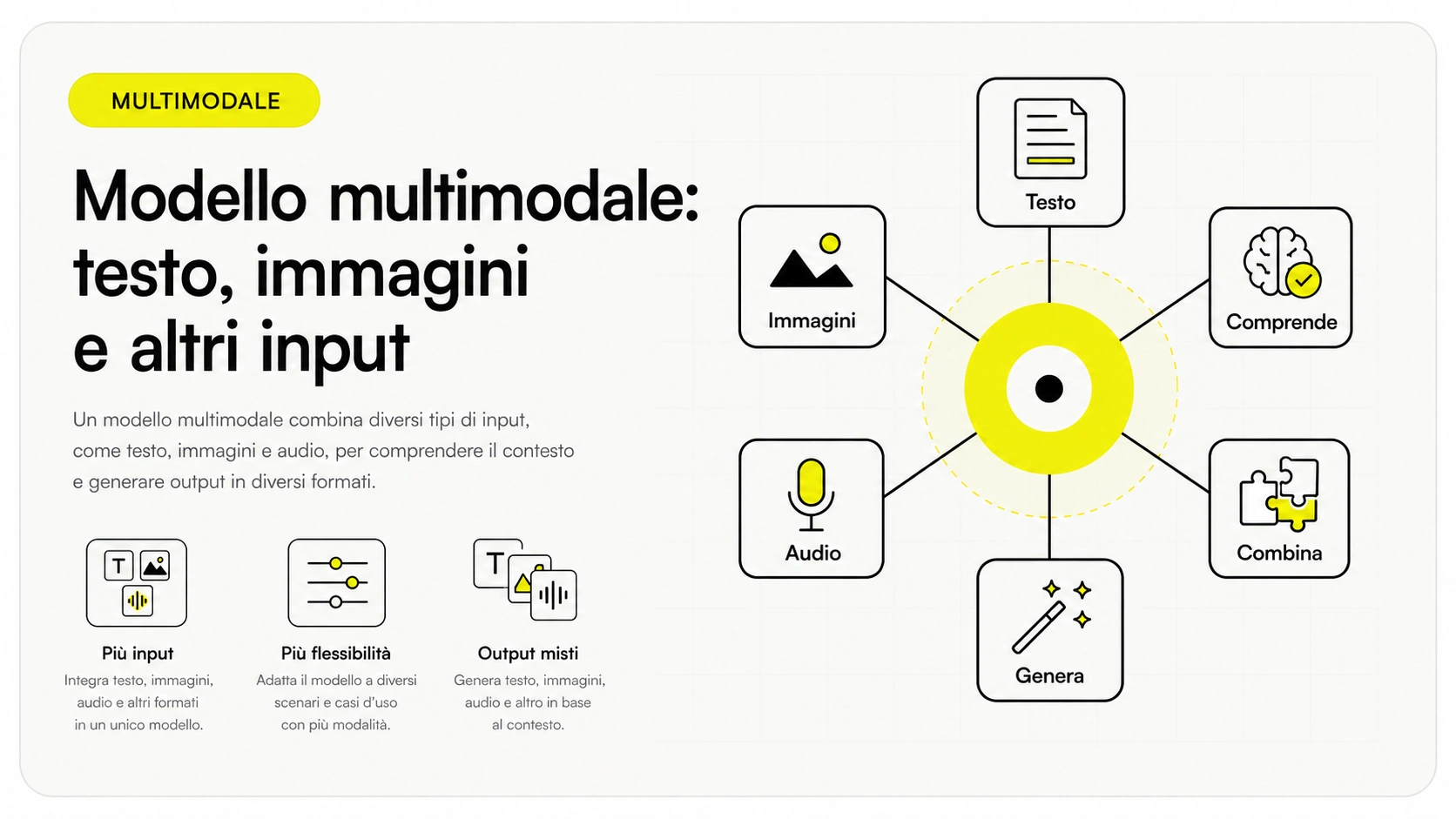
Perché "lo spazio comune" è il vero trucco
Il passaggio che fa la differenza è il secondo. Finché testo, immagini e audio restano in formati separati, non puoi confrontarli. Portandoli tutti in uno spazio numerico condiviso, il modello può misurare quanto due cose sono "vicine" di significato, anche se appartengono a modalità diverse. È lo stesso principio degli embedding, esteso oltre il testo.
Questo spiega perché un modello multimodale può rispondere a "trova nella foto l'oggetto descritto in questa frase": confronta la rappresentazione della frase con quella delle regioni dell'immagine e sceglie la più vicina.
Non è magia: i limiti restano
Il modello non "capisce" l'immagine come una persona. Riconosce schemi visti durante l'addestramento. Se gli mostri un grafico fatto male, una scritta a mano poco leggibile o un audio con rumore di fondo, la rappresentazione è imprecisa e la risposta ne risente. Vale anche qui il principio delle allucinazioni AI: può descrivere con sicurezza dettagli che nell'immagine non ci sono.
AI multimodale e modelli AI: dove si colloca
L'AI multimodale non è una tecnologia separata: è un'evoluzione dei grandi modelli che già conosci. Quasi tutti i principali assistenti generalisti sono diventati multimodali, ed è per questo che spesso non devi adottare nulla di nuovo. Per orientarti tra le opzioni puoi partire dalla guida ai principali modelli AI; qui basta capire le famiglie.
| Tipo di sistema | Cosa accetta in ingresso | Esempio d'uso |
|---|---|---|
| Modello solo testo | Solo testo | Scrivere una email, riassumere un testo incollato |
| Modello multimodale (testo + immagini) | Testo e immagini | Leggere una fattura fotografata, descrivere una foto prodotto |
| Modello multimodale con audio | Testo, immagini, audio | Trascrivere una riunione, rispondere a una domanda vocale |
| Modello con output generativo | Testo (+ immagini) in ingresso | Generare un'immagine da una descrizione, produrre voce sintetica |
| Sistema specializzato (OCR, visione dedicata) | Un solo formato, ottimizzato | Controllo qualità su una linea, lettura targhe ad alta precisione |
La regola pratica: per la maggior parte dei casi aziendali quotidiani basta un buon assistente multimodale generalista. I sistemi specializzati servono quando hai bisogno di altissima precisione su un compito ristretto e ripetuto migliaia di volte.
A cosa serve l'AI multimodale in azienda
Il valore non è "fare cose nuove e futuristiche", ma eliminare passaggi tra strumenti diversi. Prima servivano tre tool separati — uno per leggere il documento, uno per trascrivere l'audio, uno per scrivere il riassunto. Ora un solo modello fa da ponte. Questo riduce gli errori di "travaso" e il tempo perso a copiare dati da un'app all'altra.
- Documenti fotografati: leggere una fattura, una bolla o un contratto scattati col telefono ed estrarne i dati chiave.
- Immagini di prodotto: generare una prima descrizione partendo dalla foto reale dell'articolo, non da aggettivi inventati.
- Audio e riunioni: trascrivere una call, ricavarne i punti decisi e le azioni da fare.
- Assistenza visiva: un cliente manda la foto di un pezzo rotto e il sistema suggerisce il ricambio o la procedura.
- Controllo coerenza: confrontare un'immagine con una scheda tecnica per segnalare differenze evidenti.
Il filo comune resta lo stesso dell'AI in generale: il modello gestisce la parte ripetitiva (leggere, trascrivere, estrarre, abbozzare), la persona mantiene la decisione finale sui punti che contano. Quando questo equilibrio è chiaro, il risparmio di tempo è misurabile.
Esempi pratici (testo + immagine + audio)
Tre scenari realistici di PMI e professionisti italiani, uno per ciascuna modalità.
1. Testo + immagine — officina che gestisce ricambi. Un cliente invia su WhatsApp la foto di un pezzo da sostituire con un messaggio scritto ("mi serve questo, è di una Panda del 2018"). Il sistema multimodale legge insieme foto e testo, propone il codice ricambio più probabile e prepara la bozza di risposta con prezzo e disponibilità. Il meccanico conferma o corregge. Si elimina il giro di telefonate per capire "di che pezzo parliamo".
2. Immagine + testo — e-commerce di arredamento. Per un catalogo di centinaia di articoli, l'AI guarda la foto reale del prodotto e la scheda tecnica, poi scrive una prima descrizione coerente con ciò che si vede (materiale, colore, stile), invece di inventare. Il team rivede e pubblica. Si abbatte il tempo della prima stesura senza perdere aderenza al prodotto.
3. Audio + testo — studio di consulenza. Dopo una riunione con il cliente, il consulente carica la registrazione. Il modello trascrive, individua i punti decisi e prepara un riassunto con le azioni assegnate. Il professionista controlla nomi, importi e scadenze prima di inviarlo. Da un'ora di call si ottiene in pochi minuti una bozza di verbale già strutturata.
In tutti e tre i casi il punto non è "l'AI fa tutto", ma "l'AI mette insieme formati diversi e prepara, l'umano decide". È il modello che funziona, applicato a AI generativa e dati reali.
Quando ha senso usarla e quando no
Quando l'AI multimodale conviene
- Hai input in formati diversi che oggi gestisci a mano (foto, audio, PDF).
- Il compito è ripetitivo e ad alto volume (tante fatture, tante foto, tante call).
- Un piccolo margine d'errore è tollerabile o c'è una revisione umana.
- Vuoi ridurre i passaggi tra strumenti separati e gli errori di copia-incolla.
Quando evitarla (per ora)
- Serve precisione assoluta su ogni singolo numero e non c'è controllo umano.
- Le immagini o gli audio sono di pessima qualità (sfocati, rumorosi, scritti a mano).
- I dati sono riservati e lo strumento non offre garanzie su privacy e GDPR.
- Stai aggiungendo modalità per moda, senza un processo misurabile dietro.
Regola pratica: la modalità in più non sistema un processo confuso, lo accelera. Se il flusso di lavoro è già caotico, aggiungere foto e audio non lo rende migliore — lo rende caotico più in fretta. Prima si definisce il processo, poi si sceglie quante modalità servono davvero.
Domanda frequente: "Multimodale" vuol dire che genera anche immagini e voce?
Non sempre. Molti modelli sono multimodali in ingresso (capiscono foto e audio) ma producono solo testo in uscita. La generazione di immagini o voce è una capacità separata, che alcuni modelli hanno e altri no. Quando valuti uno strumento, distingui sempre cosa accetta da cosa produce: per la maggior parte dei casi aziendali conta soprattutto la prima.
Errori da evitare
- Fidarsi di ciò che il modello "vede" senza verificare. Numeri letti da una foto, importi su una bolletta, codici scritti a mano: vanno sempre controllati. Un errore di lettura si propaga in tutto il processo a valle.
- Caricare dati riservati su strumenti pubblici. Foto di documenti con dati personali, contratti, schede clienti: negli strumenti gratuiti possono essere usati per addestramento. Servono regole interne e, dove serve, un piano business o un'integrazione via API AI.
- Dare per scontata la qualità dell'input. Foto sfocate, audio coperto dal rumore, scansioni storte: la risposta è buona quanto l'input. Spesso conviene migliorare la fonte prima del modello.
- Pretendere output multimodale quando ti serve solo input. Inseguire la generazione di immagini o voce quando il tuo problema è "leggere documenti" è sprecare budget su una capacità che non userai.
- Saltare la misurazione. Senza un "prima" e un "dopo" (minuti per documento, errori evitati) non saprai se la modalità in più ti dà valore reale o solo l'effetto wow.
Come applicarlo in azienda
Introdurre l'AI multimodale segue lo stesso percorso breve e ripetibile di qualsiasi automazione sensata: si parte dal problema, non dalla tecnologia.
- Individua un input non-testuale che gestisci a mano. Fatture fotografate, foto prodotto, registrazioni di call: dove perdi più tempo a "tradurre" un formato in dati?
- Misura il punto di partenza. Quanti minuti per documento o per audio oggi, quanti errori. Senza numeri non c'è ROI.
- Parti dallo strumento che hai già. Spesso l'assistente multimodale che usi per il testo accetta anche immagini e file: provalo prima di comprare altro.
- Tieni l'umano nel controllo. Il modello legge e abbozza, la persona verifica i dati critici e approva. Soprattutto all'inizio.
- Misura di nuovo e decidi. Se i numeri migliorano, estendi il flusso o collegalo agli altri strumenti con un'automazione dei processi; se no, cambia approccio.
Quando il caso d'uso si stabilizza, il passo successivo è incastonarlo nel flusso reale: un agente AI che riceve la foto via email, estrae i dati, aggiorna il gestionale e prepara la risposta. È qui che la modalità in più smette di essere una curiosità e diventa tempo risparmiato ogni giorno.
Conclusione
L'AI multimodale non è una nuova tecnologia esotica: è l'estensione dei modelli che già usi, capaci ora di leggere immagini, ascoltare audio e collegarli al testo dentro lo stesso sistema. Il valore per una PMI è concreto e poco appariscente — meno strumenti separati, meno copia-incolla, meno errori di travaso tra un'app e l'altra. Come sempre, conta scegliere il processo giusto, tenere la persona dove servono giudizio e responsabilità, e misurare il risultato. Da qui puoi proseguire con i modelli AI principali e con le basi dell'intelligenza artificiale per vedere come questi mattoni si incastrano tra loro.
Vuoi capire quali processi della tua azienda possono essere automatizzati con l'AI? Giallo Studio può aiutarti a trasformare il problema in un workflow reale — oppure dai un'occhiata agli esperimenti del The Lab.
Risorse correlate

FAQ
Che cos'è l'AI multimodale in parole semplici?
L'AI multimodale è un modello capace di lavorare con più tipi di dato insieme: testo, immagini, audio e a volte video, dentro lo stesso sistema. Puoi mostrargli una foto e farci una domanda a voce, oppure dargli un PDF e chiedere un riassunto: tratta tutto come parte della stessa conversazione, senza che tu debba usare strumenti separati.
Qual è la differenza tra AI multimodale e un normale chatbot di testo?
Un chatbot di testo capisce e produce solo parole. Un modello multimodale capisce anche immagini, audio e documenti, e può combinarli: per esempio leggere una bolletta fotografata e spiegarla, o ascoltare una chiamata e scriverne il riassunto. È la stessa famiglia di modelli linguistici, estesa ad altri tipi di input.
L'AI multimodale può sbagliare a leggere un'immagine o un audio?
Sì. Può fraintendere numeri scritti a mano, dettagli piccoli in una foto, audio disturbato o accenti marcati. Come ogni AI produce la risposta più probabile, non quella certamente corretta. Sui dati critici (importi, codici, scadenze) serve sempre una verifica umana prima di usare il risultato.
Quali strumenti di AI multimodale può usare una PMI?
I principali assistenti generalisti (ChatGPT, Claude, Gemini e simili) sono già multimodali: accettano immagini, file e in alcuni casi voce. Una PMI può partire da questi per analizzare documenti fotografati, descrivere immagini di prodotto o trascrivere riunioni, senza costruire nulla da zero. Verifica sempre sulla pagina ufficiale quali formati supporta il piano che usi.
L'AI multimodale è sicura per documenti aziendali riservati?
Dipende dallo strumento e dal piano. Negli strumenti pubblici gratuiti i dati possono essere usati per addestramento; nei piani business e tramite API spesso no. Prima di caricare fatture, contratti o foto con dati personali, controlla le condizioni del fornitore e definisci regole interne su cosa si può condividere, per restare conformi al GDPR.
Serve un modello diverso per ogni tipo di dato?
Non più. Un tempo servivano strumenti separati (uno per il testo, uno per le immagini, uno per l'audio). Oggi un singolo modello multimodale gestisce più formati insieme, riducendo i passaggi e gli errori di travaso tra un tool e l'altro. Restano casi specialistici in cui un modello dedicato lavora meglio.