Cluster · token AI
Token AI: cosa sono e perché contano
Cosa sono i token AI, come funzionano finestra di contesto e costi delle API, con esempi e una tabella illustrativa per stimare la spesa in azienda.
Tempo di lettura: 9 min
Guida operativa · Fondamenta AI
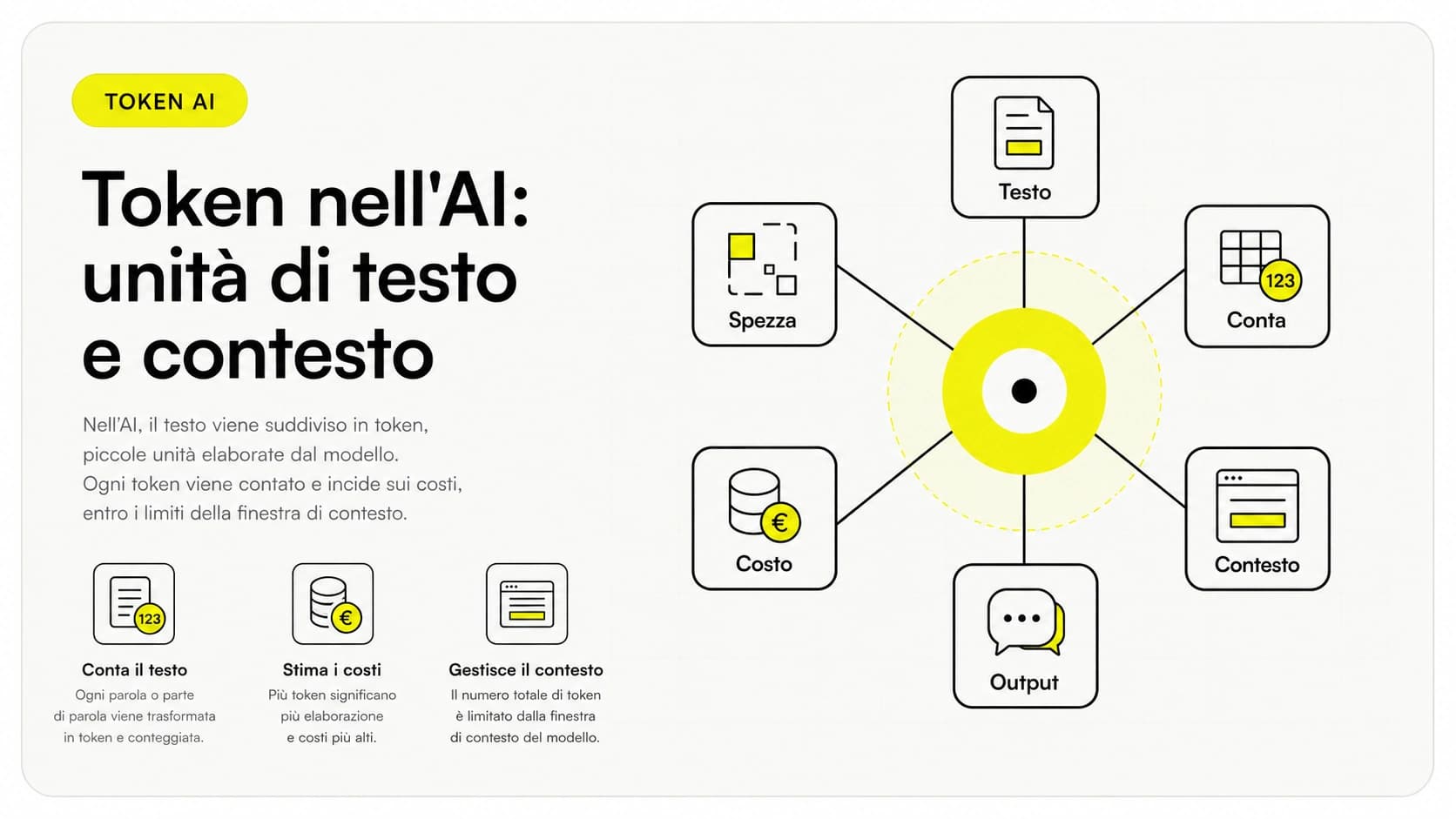
I token AI sono le unità minime di testo in cui un modello di intelligenza artificiale divide tutto ciò che legge e scrive. Non sono parole intere: una parola lunga può diventare più token, mentre una parola breve e frequente ne occupa uno solo. Quando scrivi a ChatGPT, Claude o Gemini, il tuo messaggio viene spezzato in token, il modello li elabora uno dopo l'altro e genera la risposta sempre un token alla volta.
Capire i token non è un dettaglio tecnico per addetti ai lavori. È la chiave per due cose molto concrete: quanto materiale puoi dare in pasto al modello in una volta (la finestra di contesto) e quanto ti costa usarlo via API (la spesa è proporzionale ai token). Chi ignora questo concetto finisce per allegare interi documenti inutili, pagare bollette imprevedibili e chiedersi perché l'AI "dimentica" pezzi della conversazione.
In questa guida vediamo cosa sono davvero i token, come funziona la finestra di contesto, in che modo i token determinano il costo delle API e come tenerli sotto controllo in azienda.
In sintesi
- I token sono i frammenti di testo in cui il modello divide input e output: spesso una parola vale più di un token.
- In italiano una stima pratica è 1,5-2 token per parola; una pagina (circa 500 parole) si aggira sui 750-1.000 token.
- La finestra di contesto è il numero massimo di token che il modello tiene in memoria: prompt, documenti e risposta insieme. Superato il limite, dimentica le parti più vecchie.
- Le API AI si pagano a token, con tariffe diverse per input e output (l'output di solito costa di più).
- Prompt sintetici, contesto mirato e risposte di lunghezza controllata riducono direttamente il costo senza sacrificare la qualità.
Cosa sono i token AI, concretamente
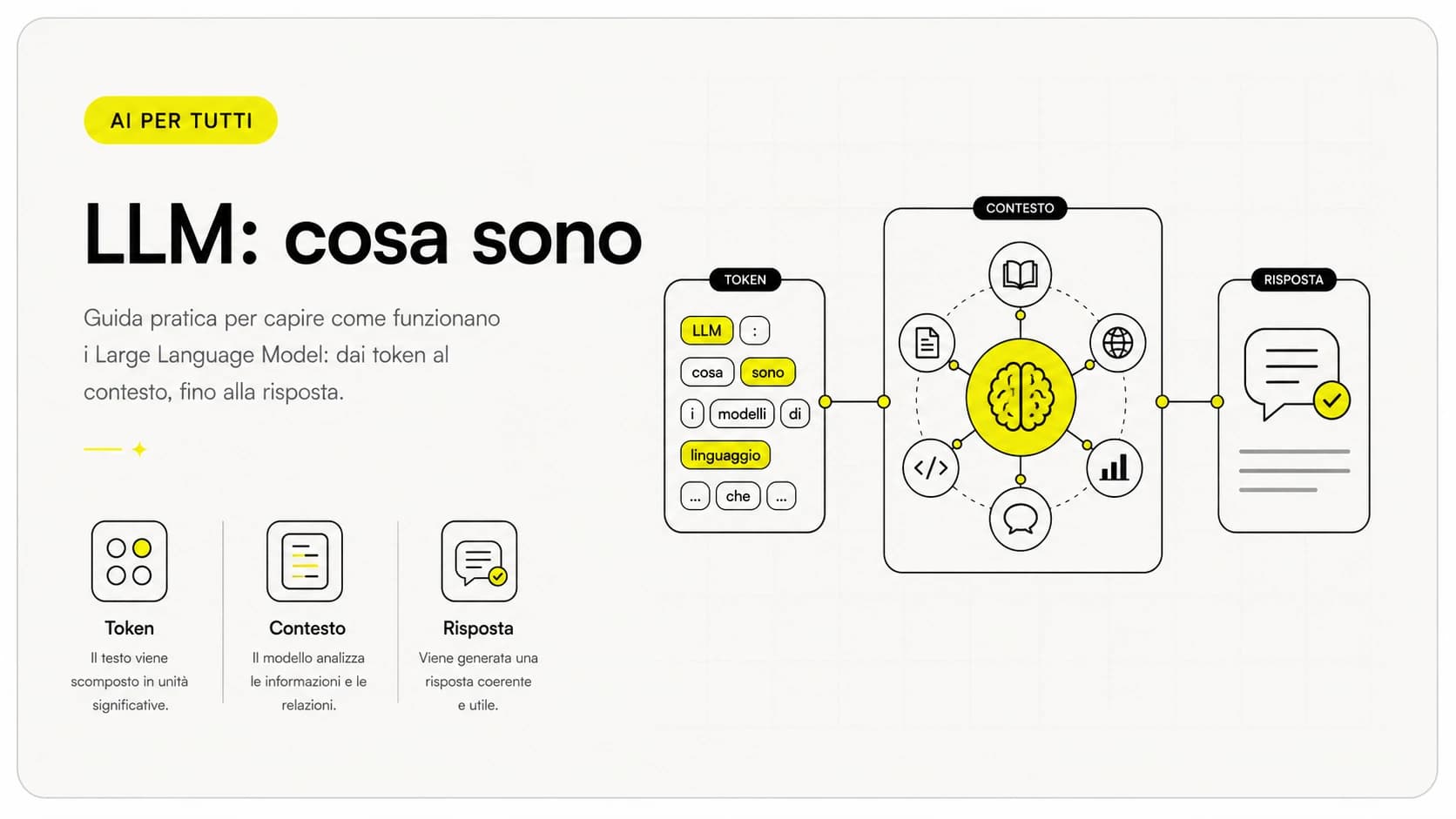
Un modello linguistico non "legge" lettere o parole come facciamo noi. Prima di tutto trasforma il testo in token, attraverso un processo chiamato tokenizzazione. Un token è in media un pezzo di parola: a seconda della lingua e della frequenza, può essere una parola intera, una sillaba, un suffisso o persino un singolo carattere.
Qualche esempio rende l'idea. In inglese, "cat" è un token solo. In italiano, una parola comune come "casa" spesso è un token, mentre "automaticamente" può essere spezzata in tre o quattro token ("autom", "atic", "amente"). Anche gli spazi, la punteggiatura e gli a-capo contano: ogni elemento del testo finisce in qualche token.
Questo spiega perché l'italiano consuma più token dell'inglese a parità di significato: le nostre parole sono mediamente più lunghe e ricche di flessioni (plurali, coniugazioni, articoli attaccati). Una stessa frase tradotta può costare il 20-40% di token in più rispetto all'originale inglese. È un dettaglio che pesa quando moltiplichi per migliaia di richieste al mese.
Per i grandi modelli linguistici che usiamo ogni giorno, il token è l'unità di lavoro fondamentale: per saperne di più sul funzionamento di questi sistemi puoi leggere la guida su cosa sono gli LLM.
Perché il modello lavora "un token alla volta"
Quando un modello genera una risposta, non la scrive tutta insieme: predice il token successivo più probabile, lo aggiunge, e ripete il processo guardando tutto ciò che ha scritto fino a quel momento. È per questo che vedi la risposta comparire progressivamente, parola dopo parola.
Questa meccanica ha due conseguenze pratiche. La prima: una risposta lunga richiede più passaggi, quindi più tempo e più costo. La seconda: il modello tiene "in vista" solo ciò che rientra nella sua finestra di contesto. Tutto parte da qui.
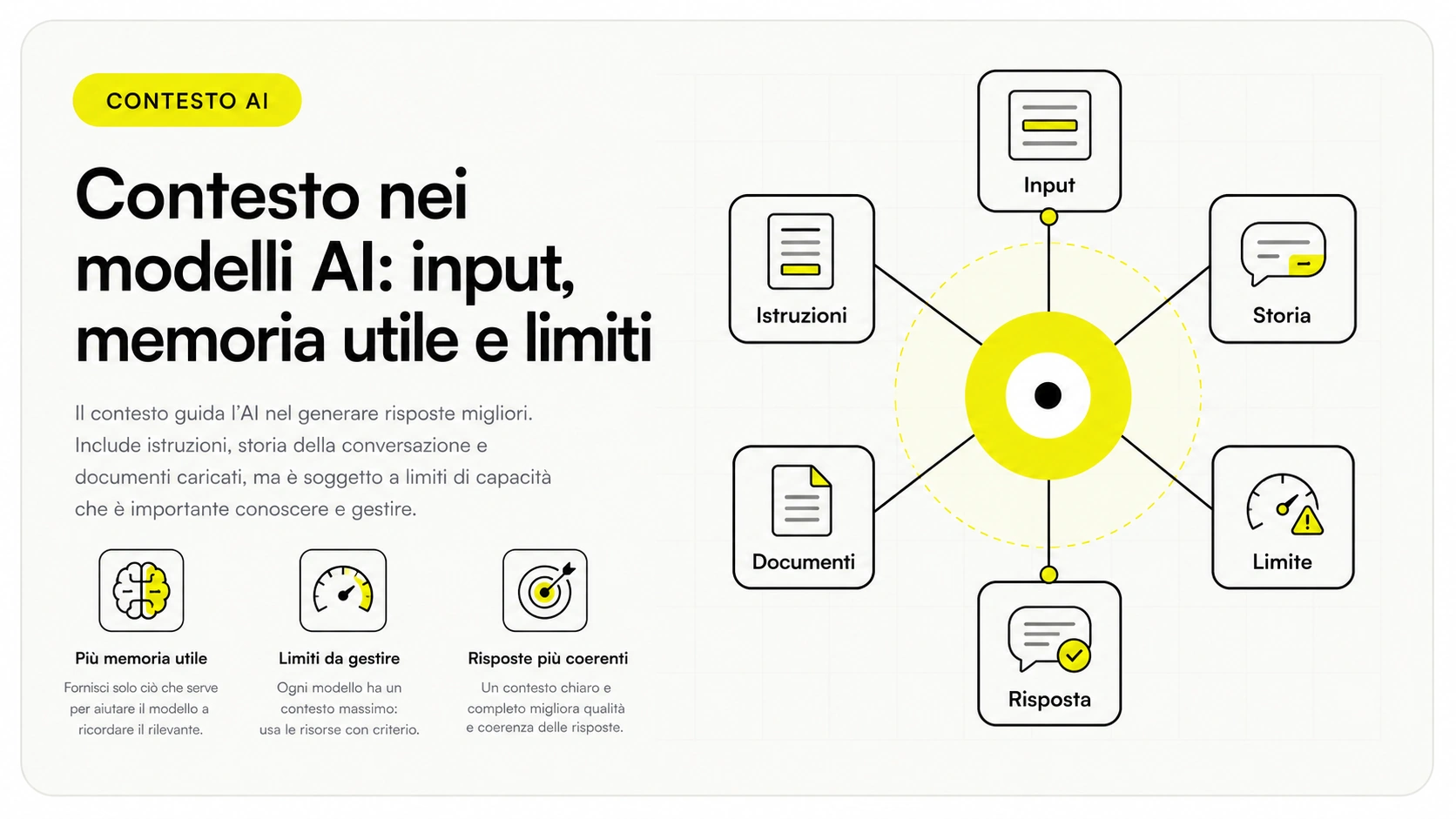
Cos'è la finestra di contesto (e perché conta)
La finestra di contesto (in inglese context window) è la quantità massima di token che un modello può considerare in una singola interazione. Include tutto: le istruzioni di sistema, il tuo prompt, gli eventuali documenti che alleghi, la cronologia della conversazione e la risposta che il modello deve produrre. Tutto questo deve stare dentro il limite.
I modelli recenti hanno finestre molto ampie — si parla di decine o centinaia di migliaia di token, e in alcuni casi oltre il milione. Ma "ampia" non significa "infinita" né "gratis": più contesto carichi, più token paghi e più rischi che il modello si perda tra le informazioni.
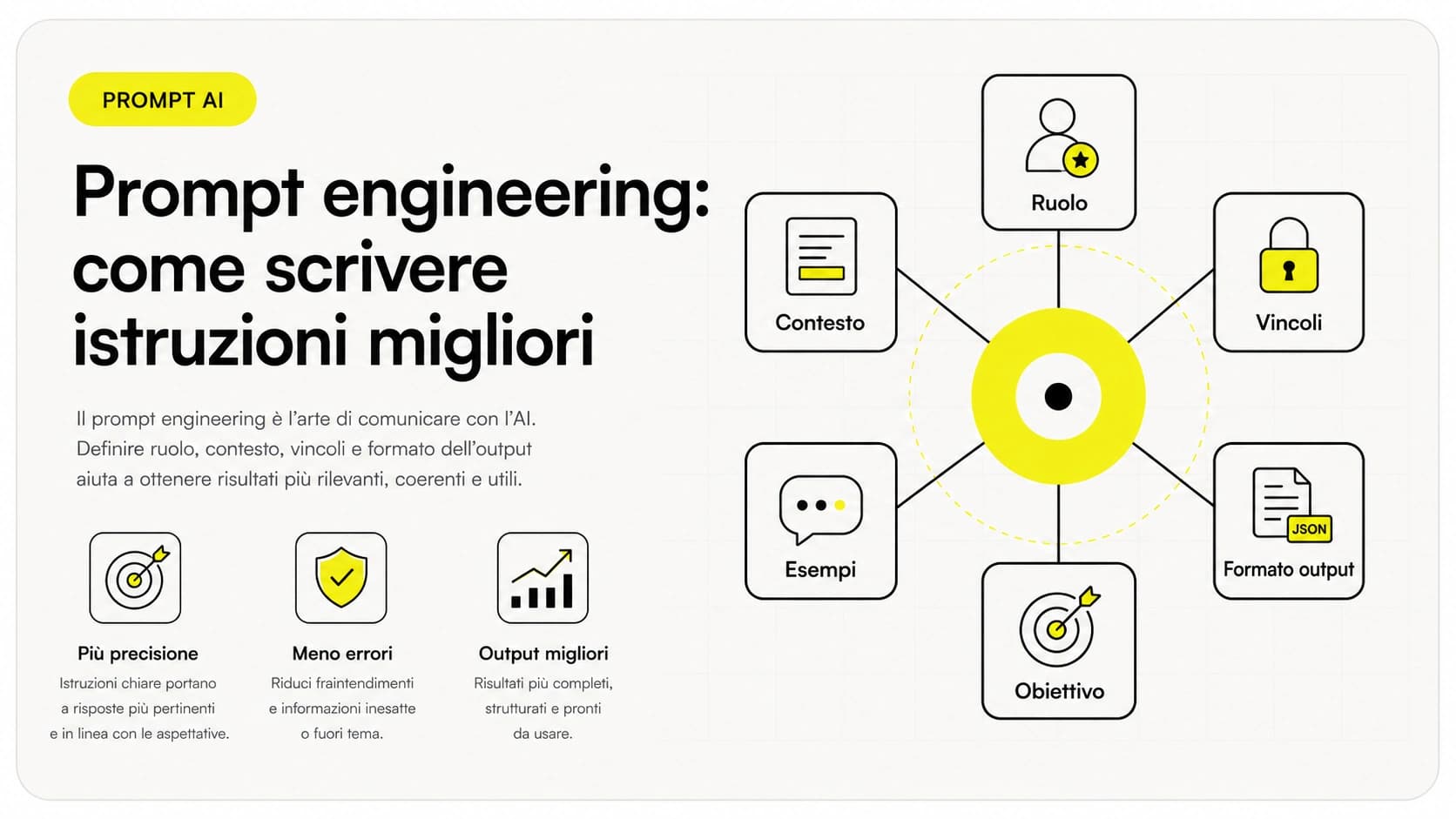
Capire questo limite è ciò che distingue un prompt efficace da uno che spreca contesto. Su come strutturare le richieste in modo mirato trovi indicazioni nella guida al prompt engineering.
Come i token determinano il costo delle API AI
Qui sta il punto che tocca direttamente il portafoglio. Quando usi un modello AI tramite API — cioè quando lo integri in un software, un'automazione o un agente invece di chattarci a mano — quasi tutti i fornitori applicano una tariffa a token. E lo fanno distinguendo due voci:
- Token in ingresso (input): tutto ciò che invii al modello — prompt, istruzioni, documenti, cronologia.
- Token in uscita (output): la risposta generata dal modello.
L'output costa quasi sempre più dell'input, perché generarlo è computazionalmente più oneroso. Il prezzo si esprime di norma per milione di token. La logica è semplice: ogni chiamata all'API costa (token input × tariffa input) + (token output × tariffa output).
Per dare un ordine di grandezza — e solo a scopo illustrativo — ecco una mini-tabella di esempio. I numeri qui sotto sono inventati per spiegare il meccanismo, non sono listini reali. I prezzi cambiano spesso e variano da modello a modello: verifica sempre la pagina ufficiale del fornitore che intendi usare.
| Tipo di modello (esempio illustrativo) | Costo input (per 1M token) | Costo output (per 1M token) | Costo stimato di 1.000 richieste* |
|---|---|---|---|
| Modello piccolo / economico | ~0,15 $ | ~0,60 $ | ~0,30 $ |
| Modello medio | ~1,00 $ | ~3,00 $ | ~1,80 $ |
| Modello grande / di punta | ~5,00 $ | ~15,00 $ | ~9,00 $ |
*Ipotesi della colonna finale: 500 token di input e 300 di output per richiesta. Valori puramente didattici: per i prezzi reali consulta sempre le pagine ufficiali dei fornitori (OpenAI, Anthropic, Google e simili), perché tariffe, modelli e regole di conteggio cambiano nel tempo.
La lettura pratica è questa: la differenza tra un modello piccolo e uno di punta può essere di 20-30 volte sul costo per richiesta. Per molti compiti semplici (classificare un'email, estrarre un dato, riassumere un testo breve) un modello economico basta e avanza. Riservi il modello grande ai compiti che lo richiedono davvero. La scelta del modello giusto per ogni compito è un tema a sé, trattato nella guida ai principali modelli AI.
Se vuoi capire come queste chiamate si integrano in un software reale, la guida su cosa sono le API AI spiega il meccanismo lato sviluppo.
Quanto costa "davvero" un caso d'uso
Il costo per singola chiamata sembra ridicolo — frazioni di centesimo. L'effetto si vede sul volume. Un assistente clienti che gestisce 5.000 conversazioni al mese, ognuna con qualche scambio e magari un documento di contesto, può passare da pochi euro a diverse centinaia a seconda del modello e di quanti token bruci per richiesta.
La regola spannometrica per stimare in anticipo: numero di richieste mensili × token medi per richiesta × tariffa. Anche grossolana, questa moltiplicazione ti evita la sorpresa in fattura ed è il primo calcolo da fare prima di mettere in produzione qualsiasi automazione AI.
Esempi pratici
Tre scenari realistici di PMI italiane, per vedere i token in azione.
1. Studio commercialista — riassunto di documenti. Lo studio vuole far riassumere all'AI dei contratti di 20 pagine. Ogni contratto vale circa 15.000 token di input. Se li passa tutti interi a un modello di punta, 200 contratti al mese diventano un costo non banale. La soluzione: estrarre prima solo le sezioni rilevanti (poche migliaia di token) e usare un modello medio. Stessa qualità sui punti che contano, costo ridotto di un ordine di grandezza.
2. E-commerce — descrizioni prodotto. Per generare 800 descrizioni, il prompt include scheda tecnica (input) più la descrizione generata (output). Tenere il prompt asciutto e limitare la descrizione a 120 parole circa controlla i token in uscita — la voce più cara. Mille descrizioni a costo prevedibile, invece di una spesa "a sorpresa".
3. Azienda di servizi — assistente sulla knowledge base. L'azienda ha 300 documenti interni. Passarli tutti al modello a ogni domanda sfonderebbe qualsiasi finestra di contesto e qualsiasi budget. Qui serve un sistema RAG che recupera solo i 3-4 paragrafi pertinenti e li mette nel prompt: poche migliaia di token per risposta invece di milioni. Il contesto giusto, non tutto il contesto.
In tutti e tre i casi il principio è lo stesso: non dare al modello più di quanto serve. Meno token inutili significa meno costo, meno latenza e spesso risposte migliori.
Errori da evitare
- Allegare interi PDF "per sicurezza". Caricare un documento di 50 pagine quando ne servono 2 paragrafi gonfia i token di input a ogni chiamata e fa lievitare il costo senza migliorare la risposta. Passa solo ciò che è rilevante.
- Ignorare il costo dell'output. Molti ottimizzano il prompt e dimenticano che la risposta è la voce più cara. Chiedere risposte concise (o porre un limite di lunghezza) taglia la spesa più di quanto si pensi.
- Usare il modello di punta per tutto. Far classificare un'email a un modello da 15 $/milione è come usare un camion per portare la spesa. Per i compiti semplici il modello piccolo è 20-30 volte più economico e ugualmente valido.
- Non stimare i token prima di andare in produzione. Senza un calcolo a priori (richieste × token × tariffa) la fattura mensile diventa imprevedibile. Una stima grossolana fatta prima vale più di una sorpresa dopo.
- Confondere parole e token. Ragionare "tanto sono solo 100 parole" porta a sottostimare: in italiano quelle 100 parole sono spesso 150-200 token. Per numeri precisi usa il tokenizer ufficiale del fornitore.
Come applicarlo in azienda
Tenere i token sotto controllo non è un esercizio teorico: è ciò che rende un progetto AI sostenibile nel tempo invece di una bolletta che cresce senza spiegazione. Ecco un percorso pratico.
- Stima i token del caso d'uso. Prendi un esempio reale di richiesta e risposta, contali con il tokenizer ufficiale del fornitore e moltiplica per il volume mensile previsto.
- Scegli il modello in base al compito. Compito semplice e ad alto volume → modello piccolo. Compito complesso e a basso volume → modello grande. Quasi mai il contrario.
- Riduci il contesto al minimo utile. Allega solo le parti rilevanti dei documenti. Dove i documenti sono molti, usa un recupero mirato (RAG) invece di passare tutto.
- Controlla la lunghezza dell'output. Imposta un tetto alla risposta dove ha senso: è la leva più diretta sul costo, perché l'output costa di più.
- Monitora la spesa reale. Tieni d'occhio il consumo di token nei primi mesi e confrontalo con la stima. Se diverge, capisci dove si bruciano token di troppo.
Questo è esattamente il tipo di lavoro su cui interviene una consulenza di automazione: progettare il flusso in modo che consumi il giusto, scegliere il modello adatto a ogni passaggio e rendere la spesa prevedibile. Se stai partendo da zero, la guida AI per aziende inquadra processi, costi e priorità.
Come conto i token di un testo senza scrivere codice?
I principali fornitori mettono a disposizione un tokenizer online: incolli il testo e ti dice quanti token vale per i loro modelli. È lo strumento corretto per le stime, perché ogni famiglia di modelli tokenizza in modo leggermente diverso. La regola "1,5-2 token per parola in italiano" va bene per un calcolo al volo, ma per un preventivo serio conta i token veri.
Conclusione
I token AI sono l'unità di misura nascosta dietro ogni interazione con un modello: determinano quanto materiale puoi elaborare in una volta (la finestra di contesto) e quanto spendi quando integri l'AI via API. Capirli ti dà due superpoteri molto pratici: progettare prompt che non sprecano contesto e prevedere la spesa prima di trovarla in fattura. Il principio guida è sempre lo stesso — dai al modello il giusto, non il massimo — perché meno token inutili significa meno costo, meno latenza e spesso risposte più precise. Da qui puoi proseguire con il prompt engineering per scrivere richieste efficienti e con la guida alle API AI per vedere come tutto questo entra in un software reale.
Se vuoi passare dai test con ChatGPT a un sistema AI integrato nei processi aziendali, Giallo Studio progetta agenti e automazioni su misura — calibrati anche sul consumo di token, così la spesa resta sotto controllo.
Risorse correlate

FAQ
Cosa sono i token AI in parole semplici?
I token sono i pezzi di testo in cui un modello AI divide ciò che legge e scrive. Non sono parole intere: spesso una parola lunga viene spezzata in più token, mentre parole brevi e comuni ne occupano uno solo. Il modello legge e produce testo un token alla volta, quindi tutto ciò che fai con l'AI si misura in token.
Quanti token corrisponde una parola in italiano?
Non c'è un rapporto fisso, ma come stima pratica una parola italiana vale spesso 1,5-2 token, perché l'italiano ha parole più lunghe e flessioni che vengono spezzate. Una pagina di testo (circa 500 parole) si aggira sui 750-1.000 token. È una regola spannometrica: per numeri precisi usa il tokenizer ufficiale del fornitore.
Cos'è la finestra di contesto?
La finestra di contesto (context window) è la quantità massima di token che un modello può tenere in memoria in una singola conversazione o richiesta: comprende il tuo prompt, i documenti allegati e la risposta. Quando superi questo limite, il modello dimentica le parti più vecchie. È il vincolo che decide quanto materiale puoi dargli da elaborare in una volta.
Come influiscono i token sul costo delle API AI?
Le API AI si pagano quasi sempre a token: una tariffa per i token in ingresso (input, cioè prompt e contesto) e una, di solito più alta, per i token in uscita (output, cioè la risposta). Più testo invii e più risposte lunghe generi, più paghi. Per questo prompt sintetici e contesto mirato riducono direttamente la spesa.
Posso ridurre il consumo di token senza perdere qualità?
Sì. Le leve principali sono: prompt più asciutti, allegare solo le parti di documento davvero rilevanti invece di interi PDF, limitare la lunghezza della risposta e, dove ha senso, usare un modello più piccolo per i compiti semplici. In un sistema strutturato si recupera solo il contesto utile (approccio RAG) invece di passare tutto al modello.
I token contano anche per immagini e audio?
Sì. Nei modelli multimodali anche immagini e audio vengono convertiti in token secondo regole del fornitore: un'immagine può valere da poche centinaia a qualche migliaio di token a seconda della risoluzione. Quindi anche l'analisi di una foto o la trascrizione di un audio consuma contesto e ha un costo.